

Last week, researchers from OpenAI and Google introduced Activation Atlases, a tool that helps make sense of the inner workings of neural networks by visualizing how they see and classify different objects.
At first glance, Activation Atlases is an amusing tool helps you see the world through the eyes of AI models. But it also one of the many important efforts that are helping explain decisions made by neural networks, one of the greatest challenges of the AI industry and an important hurdle in trusting AI in critical tasks.
AI’s trust problem is real
Artificial intelligence, or namely its popular subset deep learning, is far from the only kind of software we’re using. We’ve been using software in different fields for decades.
However, because of the way it works, deep learning has made tremendous advances in areas where software has historically struggled such as speech recognition, computer vision and natural language processing.
Thanks to these advances in deep learning, AI algorithms have made inroads in critical domains such as self-driving cars, video and image analysis, healthcare and job application processing. The common denominator of all these fields is that if AI algorithms make mistakes, they can have grave impact on the safety, health and life of humans who are subject to their functionality.
All software goes through debugging and testing to make sure their users can trust them. The dramatic impact that mistakes in deep learning algorithms can have make it even more critical to make sure we can trust them.
For instance, if a self-driving car misses to detect an obstacle or another car, it can cause a fatal crash. In health care, a faulty AI algorithm might make a wrong diagnosis and treatment recommendation, negatively impacting the health of the patient. An AI-powered recruitment system might wrongly turn down a job application, unjustly depriving a qualified candidate of a career opportunity.
The engineers of AI algorithms must be able to make sure their models can be trusted to perform the critical tasks they defer to them. Likewise, the users of these systems must be able to verify how much they can trust the decisions made by the AI.
Deep learning’s transparency problem is also real


The problem with current AI technology is that contrary to classical software, where software engineers manually design and define behavior rules, deep learning algorithms have very little top-down, human-induced design. Neural networks, the fundamental structure underlying deep learning algorithms, derive their behavior from thousands and millions of training examples.
By analyzing and comparing the examples, neural networks create complex mathematical functions with thousands of parameters, which can make statistical predictions and classify new data. For instance, after analyzing thousands of cat pictures, a neural network can “look” at picture it hasn’t seen before and say how confident it is that contains a cat.
Well-trained neural networks can produce very accurate results, sometimes even better than humans. But the problem is we don’t know how they work. Even the engineers who build deep learning models often can’t make sense of the logic behind the thousands and millions of parameters that constitute the neural networks.
For instance, a neural network might have learned to classify shark images not by the physique of the sharks themselves but by the blue background of the water that surrounds them in photos. But it’s very hard to deduce that from an opaque neural network. Most times, you can only find the shortcomings of a trained deep learning model through trial and error, testing it with different samples and observing its output.
If you don’t know how a software works, you can’t know for certain how it fails, and we already mentioned some of the cases where failures in deep learning can have fatal consequences.
But the lack of transparency and explainability of AI algorithms also poses a serious problem to their end users. For instance, if a doctor is going to follow a treatment recommendation made by an AI algorithm, they should be able to verify the logic and reasoning behind that recommendation. After all, for the moment there will always be a human who will be held accountable, regardless of whether a decision involved AI algorithms or not.
OpenAI’s neural network visualizer
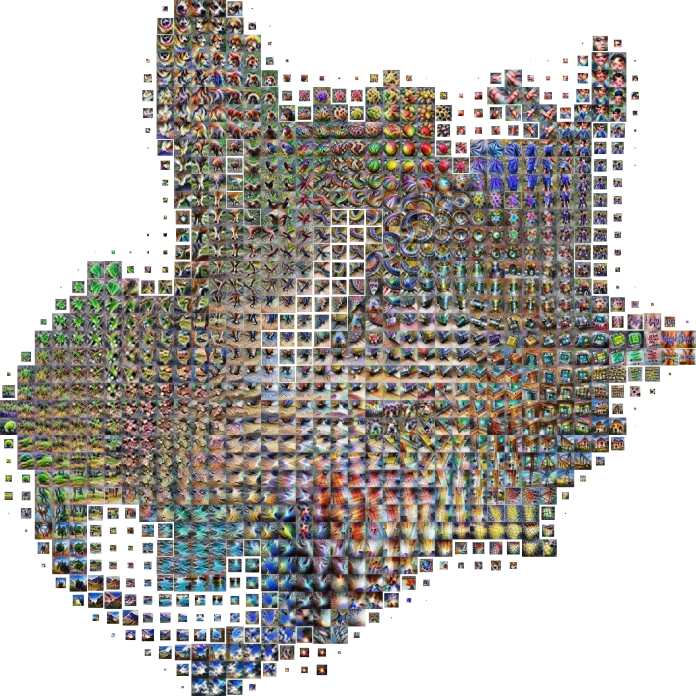
In this context, OpenAI and Google’s Activation Atlases solve a very important problem: It helps visualize how neural networks classify their data. An oversimplification of this means that the tool helps transform the thousands of numbers that compose the neural net into images, making it much easier for humans to understand their meaning. Conveniently, the team who developed the tool included Chris Olah, the one of the developers of DeepDream, a tool that used deep learning models to generate hallucinogenic images.
Activation Atlases isn’t the first tool that helps visualize the inner-workings of neural networks, but what makes it significant is that it gives a top-down view of the organization of neurons.

For instance, in the image above, we can see how the neural network categorizes images between “wok” and “frying pan.” This zoomed out view can help find problematic correlations that can result in mistakes.
A tool like Activation Atlases can help discover and fix potential vulnerabilities in neural networks. In the following example, a deep learning model was fooled into classifying a grey whale as a white shark by adding a baseball to the image.
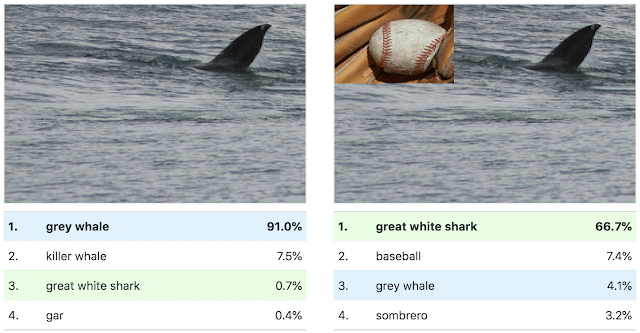
Called “adversarial perturbations,” these modifications can become dangerous in areas such as self-driving cars, where misclassifications can cause safety risks. Well-designed adversarial attacks make modifications to input data that are invisible to the human eye but force neural networks to change their output values.
With Activation Atlases, developers of artificial intelligence models can investigate their neural networks and find potential pain points that can be exploited for adversarial attacks. An investigation with Activation Atlas reveals that the previous error was due to similarities between the stitches on a baseball and the teeth of a shark which can fool the neural network.

With more tools at our disposal for investigating and explaining neural networks, we are better disposed to protect our AI models against mistakes and intentional manipulations.
Building trust in artificial intelligence
Activation Atlases is one of several efforts for creating explainable AI. As artificial intelligence finds its way into more and more fields, an increasing number of organizations are working on developing method to investigate decisions made by AI models, or AI models that are open to investigation. This includes an expansive initiative by DARPA, the research arm of the U.S. Department of Defense.
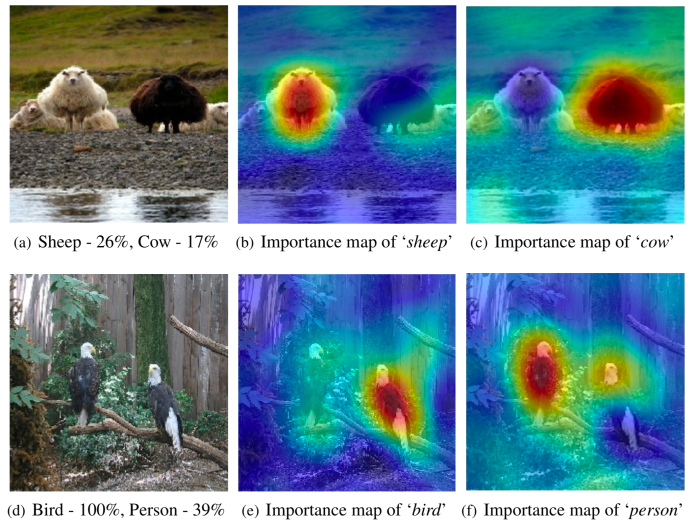
In the past year, we’ve had the chance to review some of these projects, each of which tackle the challenge of explaining AI decisions from a different angle. RISE, a method developed by researchers at Boston University, produces saliency maps that show how each pixel in an input image contribute to the output classes of a neural network. The advantage of RISE is that it is model-agnostic, which means it is not dependent on the AI model and structure used and does its work by only comparing inputs and outputs. These explainable AI methods are also known as “black box” methods.
Another interesting black box AI investigation tool is AutoZOOM, a method paper recently developed by researchers at IBM. AutoZOOM has been specially designed to help improve robustness of AI models by finding adversarial vulnerabilities with the minimum number of examples. The point of AutoZOOM is to establish trust in AI models by better understanding what are their strengths and weaknesses.
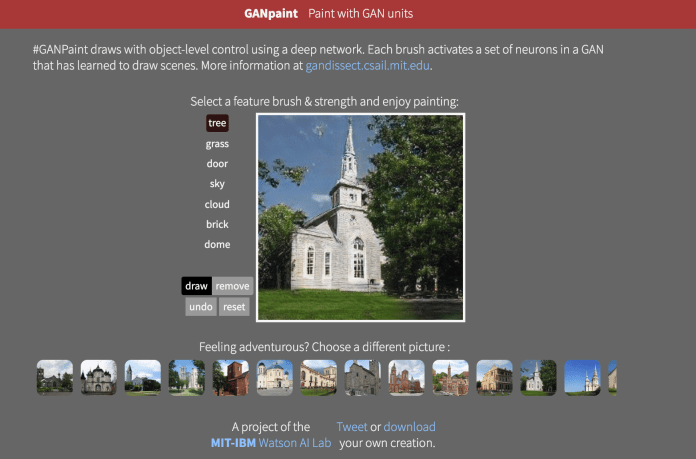
GAN Dissection, another IBM tool for visualizing the inner-workings of neural networks, has been designed to understand generative adversarial networks (GAN), a popular AI technique that is useful for creating unique creative content. GAN Dissection and its associated tool GANPaint are a step toward creating better cooperation between human operators and AI models.
Every one of these tools and the many other that are being developed are key to establishing trust in AI models by finding their strengths and weaknesses.
You must be logged in to post a comment.