
I think almost every single application in the data space, be it data orchestration, machine learning workflow management, data versioning or reporting & dashboarding has to deal with two simple problems.
- The diversity of data sources.
- The diversity of use cases/ targets.
Why is that? Because data applications naturally consist of at least three steps that ingest data, transform it in some way to add value and output some kind of data.
This diversity happens inside companies and across the whole market. It means that just like a website built on WordPress, every single implementation will be its own little snowflake. Unique, and thus no generic all-purpose solution will fit. But that, in turn, means, to put it with the words of Matt Mullenweg “It would take a lifetime to replicate the 30,000 plugins, themes,… that are what make up the WordPress ecosystem”.
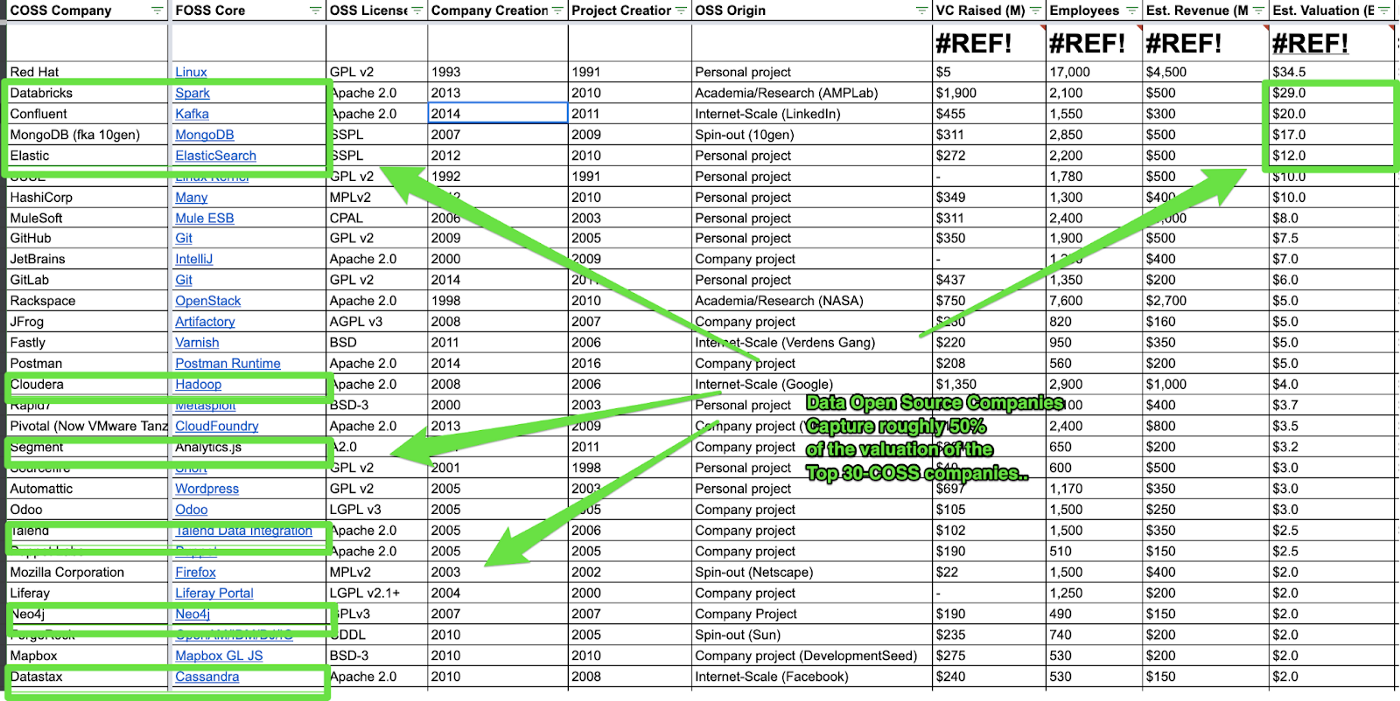
Or to put it in other words: If you’re going to look for a data ingestion tool that is able to ingest all your data, 95% of you will very likely never find a fitting tool in the closed source world. Certainly not one, that makes it its priority to gather your sources & targets. And it’s the same for every single category of data task you got at hand.
It’s not a coincidence that the distributed version control system market looks like this:
That’s a simple consequence of the nature of the market. The product hinges on open source, open-source in turn needs collaboration. The more the better, so there is network economics involved, with each participant, the marginal value rises, up to some point. That means if two people collaborate the value is say, 1$, if three collaborate it’s not 2$ but 3$, and so on.
But that means, as is also discussed in detail in the amazing book “Information Rules: A strategic guide to the network economy”, that the market will converge to one or two solutions. So at least the underlying open-source categories will always converge to something that looks like the pie chart above.
The only question is: Do you know how to be number 1 or 2? If not, you will have to abandon the open-source model at some point and migrate to something else, or at least not stake your business on it.
Business Case — Segment pivots into & then out of OSS: The company Segment was founded in 2011. They developed a Javascript tracking library called Analytics.js and built a small enterprise offering around it, around 2013 they were close to shutting down, so they decided to simply open-source Analytics.js. Turns out, this made Segment immensely popular, got them a lot of customers and a viable business model, running a huge application which at some small point uses Analytics.js. Yet if you look at the open-source project today, Analytics.js is mostly dead. Of the web analytics market, Google Analytics dominates 80–90% of it. Still, Segment managed to sidestep the open-source part and establish a viable business model with few bounds to the open-source project.
What’s the consequence for you? If you’re running an open-source affiliated data company you will end up with three options:
- be number 1 or possibly be number 2
- be segment and ignore your project, stake your business on something else
- or be the out-of-job maintainer of an abandoned open source project.
Future questions for companies like segment: The solution segment provides still does not manage to solve the diversity problem, so I suspect that sometime in the future an open-source solution will emerge that disrupts segments, current business model. The company RudderStack for instance is already entering the same market with an open-source offering.
The company Stitch has an open-source project called “Singer”. Singer is basically an attempt at an open protocol for data connectors, which is still a missing piece in the data world.
Business Case: The problem is, even though the company uses Singer to integrate it into their ETL tool, they did not manage to build a vibrant community around it. In fact, as we will discuss later, they make it pretty hard for contributors to contribute. The only good reason people use Singer currently is the lack of an alternative. Why is this a problem? It’s not generically a problem, it just means they cannot use the marketing for the open-source project or the open-source development power.
So to get an open-source project running, you need to build a vibrant community around it. You can focus on a lot of different user sets if the project is successful, but in the beginning, you’ll have to work on exactly one user segment:
people who want to use the project themselves.
Stitch went another direction in favor of monetization, which I think was a mistake for the project. As the guys at timescaleDB say, you gotta have “broad adoption & primary credibility” before you even think about monetization. Both are important to make the business behind it sustainable. So how do you get people to use your project? Besides having an awesome project? By making it as easy as possible to
- Use the project,
- contribute to the project.
Let’s take a look at another company that excels at this.
Business Case — dbt builds “Primary Credibility & Broad Adoption”: The team at dbt, a transformation-only tool based on SQL, takes building “primary credibility” seriously. They blog, hold workshops, and even free “dbt 101” events. Now that’s building “primary credibility”. Would you go to anyone else to understand how to build SQL models? I wouldn’t.
Later in the live cycle of your project, you’ll also be able to focus on other user segments, especially other companies that integrate into your ecosystem. Let’s take a final look at yet another project that nails this component.
Business Case — Building an Ecosystem of Contributors with Terraform: Terraform is an open-source tool for managing cloud infrastructure. One of the main contributors is the team behind gruntworks, who have an interest in the project because they themselves provide services on top of it. That’s the idea of getting contributors involved later on because they actually are integrated into the ecosystem. HashiCorp, the company behind Terraform, is also listed on the COSS listed above.
Ever had a question like this in your mind? “This tool looks great! The best data versioning tool on the planet, great product vision… But why in the world would I like to version my data in the first place?”
I love good product vision & data versioning. But I think the world of data is in complete turmoil. There’s a data mesh paradigm shift going on, E(t)LT replaces ETL, data as code is hopefully taking off sometime soon, machine learning is getting productionized with lots and lots of frameworks hitting the market.
Not knowing where things are headed makes it hard, even for insiders like me to understand what all these data companies & tools do, and why.
Let’s compare the tool dbt from above with another tool called TerminusDB and see why this might be the case.
Dbt summarizes dbt in the following words:
“dbt is a development environment that speaks the preferred language of data analysts everywhere — SQL. With dbt, analysts take ownership of the entire analytics engineering workflow, from writing data transformation code to deployment and documentation.”
Compare that to the teaser the “terminusDB” project provides:
“What is TerminusDB? — TerminusDB is an open-source knowledge graph database that provides reliable, private & efficient revision control & collaboration. If you want to collaborate with colleagues or build data-intensive applications, nothing will make you more productive.”
Now the question: Do you now feel like you need dbt? Compare that to terminusDB, do you need it? For me, the answers are yes & no. Let’s see why:
- Dbt: If I want to build a data pipeline, dbt tells me SQL is the future of modeling things, and dbt is the best tool to do the “transformation” part of it. I should get something else for the ingestion and serving. That sounds fair, if I like SQL I will very likely use dbt.
- terminusDB: If I want to build a “data-intensive” application, does TerminusDB tell me anything about how in the future this will be done? I’m not sure, I like the product, but that is because I believe two things will happen in the future, that is working with data as code & versioning, and more graph databases. But both points are missing from TerminusDBs presentation.
I think this is the critical bridge data companies & projects have to build to buy “prime credibility”, embrace the change in the data world, tell me how things are gonna get done now & in the future, and tell me your place in it.
After all, if you believe, like me, that ELT is the future, there’s nothing an ETL could do inside its product vision to convince me otherwise, it would have to go beyond that and convince me that ETL actually has a place.
Side note: To be fair, I talked to the terminusDB team and they seem very aware of this and are planning to redo their communication in this direction.
If you need to build “prime credibility & broad adoption” before even thinking about monetization it sounds like you can also monetize too early. Stitch as a company already took off and has a healthy customer base, Segment even more so, but for the company behind terminusDB, I am not so sure.
Business Case — Monetizing too early with TerminusDB: The company TerminusDB/DataChemist, founded in 2017 in Ireland raised around 6M USD in funding so far. They put a lot of effort into building an “always open source” graph database with data versioning and document storing capability. That sounds pretty unique. To monetize their business, they also launched the “Terminus Hub”. An application that sits on top of a TerminusDB. The problem however is now, that their open source project TerminusDB is not taking off. But the company has now diverted their manpower to building the Terminus Hub + selling it to people….
What happened here? The company might not have seen that two things don’t go well together:
- an open-source project that has not yet met “prime credibility & broad adoption”. In alone is not a problem, as you can see with Segment.
- a monetization model that depends on both, the word of mouth marketing from the open-source project as well as the project’s adoption itself.
Segment’s success did not depend on the success of Analytics.js. They basically just used the adoption to market their own product. But TerminusDB does, because they build their enterprise offering on top of their open source project. So now we have a problem.
What could they do now? Really they got two options:
- Focus back on the open-source project and get this thing to fly, make it the best versionable document graph storage in the market.
- Change the monetization model by either
- Removing the dependency with the open-source model, e.g. by opening up the Terminus Hub to all databases, graph databases, or any other dependency removal.
- Strengthening the dependencies by migrating all of Terminus Hub into the open-source project and just follow the route GitLab et al go and offer a hosted version with business & enterprise features.
Wikipedia lists a dozen “business models for open-source companies” and yet you’ll very often hear the idea that the business model for a data company will be to
- develop an open-source system that can be self-hosted
- provide paid hosting.
So where’s the dilemma? I often enjoy hosted options of open source solutions for the simple reason that running these things is often pretty expensive and complicated. Or to put it in other words, people will choose hosting, if self-hosting is more expensive for them.
But that means the open-source company has no incentives to make it easy to run their project. And yet that’s exactly what they would need to do to make the open-source project successful.
The freemium model is one way to navigate the dilemma and it’s how GitHub manages to dominate the distributed version control system market with a 60% market share. Even if git is hard to set up, you can always just choose the free hosted version so people get lots of incentives to contribute.
Some companies even take it one step further, making the setup easy and providing a freemium model like the WordPress project. Remember the “famous 5-minute setup?”. It’s what distinguished WordPress in the beginning from competitors that took 30+ minutes to set up. Turns out, WordPress also provides a freemium model. They seem to do something right.
In university, I studied a subject called “mechanism design”. It’s a subfield of broadly speaking economics that has a simple target, to design a “mechanism” that is really just a system that gets the incentives right. Design a system that provides the incentives such that if everyone acts rationally, something good will happen.
The dilemma in bare-bones hosting and the success of GitHub & GitLab showcase a simple truth:
In open-source markets, it’s all about the incentives. It’s about the systems, the open-source community, and the company you create.
GitHub and GitLab designed their companies so much in line with their open-source projects, that they have huge incentives to keep themselves involved in these projects all day long. As a result, the open-source projects also get lots and lots of contributions from the outside and a whole ecosystem around them now exists. That is an amazing self-enforcing mechanism just driven by setting the right incentives for themselves.
I’m not saying this is the only way to build a data company, but I am saying, you will very likely have to get involved in open source, and you will very likely have to think about designing good incentives for your own company and for the community.
The next option to navigate this dilemma is to provide hosting and differentiate the hosting with a bunch of extra features that are not that feasible for the open-source version. Since a lot of data things happen in command-line interfaces, a very typical option is to go with the graphical user interface for the hosted version.
But this already slightly turns the tables, companies like GitHub & GitLab manage to stay as close to the open-source project as possible which is one explanation why they together dominate 90% of their market.
Business Example Fishtown Analytics & dbt cloud: The company fishtown analytics for instance provides the transformation-only tool “dbt”. The cloud version has a free option and comes with a nice little GUI — something that is actually needed in the cloud version. In the future, they will have no problem extending this with other things like linting, testing, etc.
It seems like Fishtown is doing a great job, but I still issue a warning here, because this kind of differentiation can lead to a downfall. You can see that in the example I mention “(11) Circle the Wagons”, and before in the thought about incentives.
As said, WordPress offers both a “5-minute setup” and a free option. So they simply ignored the dilemma. So what do they charge for? They, like other successful open source companies, manage to offer a bunch of segmented hosting packages, all of which simply think about the “cost of self-hosting” for different segments. This will typically yield you something like this:
- Free for individuals.
- small amount/month for small teams, with the added benefit of 5–10 users
- much larger amount/larger teams, adding single sign-on (which is actually hard to handle yourself), connections to active directory, auto-scaling (again hard to manage yourself) etc.
As said, I like to issue a warning to simply let people “pay for the GUI”. Matt Mullenweg provided a great metaphor for which products you want people to pay for. The metaphor is called “help circle the wagons”.
So which added value product do you want people to pay for? It’s the thing you simply need to have in the cloud, the stuff you cannot self-host. In the case of Automattic it is things like JetPack (which they still provide for free) and things like Akismet, the anti-spam system. It’s stuff that needs large sets of data, machine learning, etc. to train, or it’s stuff that has some kind of economy of scale behind it, which hosting usually does as well.
Except hosting is a long-term low-margin product where added value products can carry a higher margin.
What happens if you decide to let people pay for features which could just be in the open-source version?
Business Example Singer and Stitch: As explained above, the Singer project actually was started by the company Stitch. But the company Stitch decided to keep some parts of the Singer project, namely a “testing environment” inside their paid offering. But this means, they made it harder for people to develop singer taps, plus, they incentivized themselves to work on the paid side and less on the open-source side of things. For me, these are some possible reasons why that project died.
Side note: The meltano community is currently trying to revive the Singer project by “undoing” all the missteps Singer took, like providing an SDK or testing capabilities.
The company prefect has an interesting model which is somewhat specifically designed for the data world, the “hybrid model”. It allows you to host prefect in the cloud, but still keep the data inside your own network.
The hybrid deployment idea is an important concept and can be applied to a variety of different contexts. There are a dozen reasons to keep “something” inside your own network/ architecture and hybrid models can accomplish this very easily by wrapping that part inside APIs. Hybrid deployment will at the very least increase data security & data privacy for the end user.
Business Example, the European GDPR, and RudderStack: The company RudderStack provides hosting, but it doesn’t by default deal with any of these problems. As it is by nature something that connects to lots of customer-related sources, it will channel a lot of personalized information. Meaning that inside the EU, this will cause problems with the GDPR which forces companies to transform the data at least inside the EU. Even if they allow hosting inside the EU, the amount of personal information does provide a larger security issue. So a “data hybrid model” sounds like a great idea in this case.
Side note: They do provide the option to host anywhere you want in their most expensive package, which would eliminate the GDPR problem, but not the data security one.
Another possible use of data hybrid models is to keep “repositories” out of the hosted version, but everything else in. Tools like airflow, prefect, and dagster or data integrators like meltano and stitch could greatly benefit from a cloud version which allows keeping the “repository of jobs/transformations/connections” inside the customer’s usual infrastructure. This would allow for testing, linting, versioning in the usual environment and still take almost all of the operational burden of running the solution.
Strictly speaking as a company, GitLab has little incentive to develop the meltano project further. They very likely had great incentives to develop the first few iterations of meltano, to get it to work, but once they solve for their own little “snowflake” the incentives drop.
So what then? Of course they could choose to monetize it, or they can let the project go truly open source. A common scheme lately is to donate it to the Apache Foundation which already has a lot of data open-source projects under its hat.
Question: So once GitLab abandons meltano for business reasons, there will be a big drop in both shaping the project and actual contribution. Will the project survive this drop? With the dynamic explained above, it’s a winner takes all/most market, so if there are 1–2 similar alternatives by then, meltano might simply disappear.
Since I started writing the “Three Data Point Thursday” newsletter, I observed a lot of the current startups which wrestle with the open-source space so let’s take a look at a random collection of them and how they are moving towards these problems.
Connecting to data sources & targets is still a problem that awaits a good solution. There still is no good protocol-level solution, and the open-source space is very immature. But once we get a general layer wrapping data sources & targets, I think a big change will happen in the data realm.
If you think back to 2010, there were dozens of web-hosting companies, some specializing in things like WordPress hosting, all building their own thing, creating their own codebase, and keeping that to themselves. But nowadays, these kinds of things are “wrapped” into neat little packages anyone can use & deploy on any cloud platform they choose. This “wrapping” is what currently disrupts the hosting industry. Why is that? Because in 2010 I had to pay a special provider to get a Postgres instance and a web server running. In 2021, I will get it with 2 lines of code on AWS/GCP/Azure. In 2010, these companies made money by exploiting their intellectual property, their closed codebase. Now the cloud providers “wrapped” this stuff and made it publicly available.
So what will happen, once data sources & targets get wrapped? It for one will make it extremely simple to build solutions that push data from A to B. So essentially any company that currently makes money by basically using their pile of intellectual property which consists mostly of data source & target connectors will get into rough water. This might include companies like Segment.io, Stitch, or Fivetran.
What could these companies do? At least some of them? Move heavily into the open-source market! Target specifically the “data connector” market and win the race, thus creating the ecosystem around “data connectors”. But that means doing the very opposite, opening up and enabling everyone else to freely create ETL tools on top of these connectors, which would be a big pivot as far as I understand it…
Let’s switch the random thought. The company behind prefect is heavily involved in the open-source development, but they decided to keep some “core” features like user management out of the “open core”. This seems to imply that their incentives are slightly twisted towards developing things on the “paid cloud ” edition and not so much on the open-source edition. Considering that they compete in a market of three (dagster, airflow, prefect), we could conclude that a better option would be to keep the cloud edition really close to the core edition to ensure maximum involvement in the OSS because following the outlined dynamics, there’s either maximum involvement or a dead OSS project.
If you take a look at the company preset.io they are aiming at exactly that,
“We never fork the Superset code, so you never have to worry about vendor lock-in. Easily migrate your existing Superset workloads onto Preset Cloud and vice versa.”
. Sounds like someone took a close look at the incentives they were providing for themselves here.
I really want the data world to prosper, and I really think it’s gonna happen through open source.
If you work at any of these companies and feel like I missed something you can always reach out to me via Twitter/LinkedIn etc. as said, I didn’t do too much research, so I might have gotten a few things wrong. No offense intended, tell me and I’ll correct it!
And of course thanks for the nice chats I had with a couple of founders in this world.
Besides all the great material I shared in the post, I’d like to highlight three articles:
Revisions:
- 2021–06–21 some minor changes