
In 1949, at the dawn of the computer age, the French philosopher Gabriel Marcel warned of the danger of naively applying technology to solve life’s problems.
Life, Marcel wrote in Being and Having, cannot be fixed the way you fix a flat tire. Any fix, any technique, is itself a product of that same problematic world, and is therefore problematic, and compromised.
Marcel’s admonition is often summarized in a single memorable phrase: “Life is not a problem to be solved, but a mystery to be lived.”
Despite that warning, seventy years later, artificial intelligence is the most powerful expression yet of humans’ urge to solve or improve upon human life with computers.
But what are these computer systems? As Marcel would have urged, one must ask where they come from, whether they embody the very problems they would purport to solve.
(The companion article to this article, AI in sixty seconds, offers a very quick primer for those who have no familiarity with AI, and is useful background for what follows.)
What is ethical AI?
Ethics in AI is essentially questioning, constantly investigating, and never taking for granted the technologies that are being rapidly imposed upon human life.
That questioning is made all the more urgent because of scale. AI systems are reaching tremendous size in terms of the compute power they require, and the data they consume. And their prevalence in society, both in the scale of their deployment and the level of responsibility they assume, dwarfs the presence of computing in the PC and Internet eras. At the same time, increasing scale means many aspects of the technology, especially in its deep learning form, escape the comprehension of even the most experienced practitioners.
Ethical concerns range from the esoteric, such as who is the author of an AI-created work of art; to the very real and very disturbing matter of surveillance in the hands of military authorities who can use the tools with impunity to capture and kill their fellow citizens.
SEE: Analytics: Turning big data science into business strategy (ZDNet/TechRepublic special feature) | Download the free PDF version (TechRepublic)
Somewhere in the questioning is a sliver of hope that with the right guidance, AI can help solve some of the world’s biggest problems. The same technology that may propel bias can reveal bias in hiring decisions. The same technology that is a power hog can potentially contribute answers to slow or even reverse global warming. The risks of AI at the present moment arguably outweigh the benefits, but the potential benefits are large and worth pursuing.
As Margaret Mitchell, formerly co-lead of Ethical AI at Google, has elegantly encapsulated, the key question is, “what could AI do to bring about a better society?”
AI ethics: A new urgency and controversy
Mitchell’s question would be interesting on any given day, but it comes within a context that has added urgency to the discussion.
Mitchell’s words come from a letter she wrote and posted on Google Drive following the departure of her co-lead, Timnit Gebru, in December. Gebru made clear that she was fired by Google, a claim Mitchell backs up in her letter. Jeff Dean, head of AI at Google, wrote in an internal email to staff that the company accepted the resignation of Gebru. Gebru’s former colleagues offer a neologism for the matter: Gebru was “resignated” by Google.

Margaret Mitchell [right], was fired on the heels of the removal of Timnit Gebru.
I was fired by @JeffDean for my email to Brain women and Allies. My corp account has been cutoff. So I’ve been immediately fired 🙂
— Timnit Gebru (@timnitGebru) December 3, 2020
Mitchell, who expressed outrage at how Gebru was treated by Google, was fired in February.
The departure of the top two ethics researchers at Google cast a pall over Google’s corporate ethics, to say nothing of its AI scruples.
As reported by Wired’s Tom Simonite last month, two academics invited to participate in a Google conference on safety in robotics in March withdrew from the conference in protest of the treatment of Gebru and Mitchell. A third academic said that his lab, which has received funding from Google, would no longer apply for money from Google, also in support of the two professors.
Google staff quit in February in protest of Gebru and Mitchell’s treatment, CNN’s Rachel Metz reported. And Sammy Bengio, a prominent scholar on Google’s AI team who helped to recruit Gebru, resigned this month in protest over Gebru and Mitchell’s treatment, Reuters has reported.
A petition on Medium signed by 2,695 Google staff members and 4,302 outside parties expresses support for Gebru and calls on the company to “strengthen its commitment to research integrity and to unequivocally commit to supporting research that honors the commitments made in Google’s AI Principles.”
Gebru’s situation is an example of how technology is not neutral, as the circumstances of its creation are not neutral, as MIT scholars Katlyn Turner, Danielle Wood, Catherine D’Ignazio discussed in an essay in January.
“Black women have been producing leading scholarship that challenges the dominant narratives of the AI and Tech industry: namely that technology is ahistorical, ‘evolved’, ‘neutral’ and ‘rational’ beyond the human quibbles of issues like gender, class, and race,” the authors write.
During an online discussion of AI in December, AI Debate 2, Celeste Kidd, a professor at UC Berkeley, reflecting on what had happened to Gebru, remarked, “Right now is a terrifying time in AI.”
“What Timnit experienced at Google is the norm, hearing about it is what’s unusual,” said Kidd.
The questioning of AI and how it is practiced, and the phenomenon of corporations snapping back in response, comes as the commercial and governmental implementation of AI make the stakes even greater.
AI risk in the world
Ethical issues take on greater resonance when AI expands to uses that are far afield of the original academic development of algorithms.
The industrialization of the technology is amplifying the everyday use of those algorithms. A report this month by Ryan Mac and colleagues at BuzzFeed found that “more than 7,000 individuals from nearly 2,000 public agencies nationwide have used technology from startup Clearview AI to search through millions of Americans’ faces, looking for people, including Black Lives Matter protesters, Capitol insurrectionists, petty criminals, and their own friends and family members.”
Clearview neither confirmed nor denied BuzzFeed‘s’ findings.
New devices are being put into the world that rely on machine learning forms of AI in one way or another. For example, so-called autonomous trucking is coming to highways, where a “Level 4 ADAS” tractor trailer is supposed to be able to move at highway speed on certain designated routes without a human driver.
A company making that technology, TuSimple, of San Diego, California, is going public on Nasdaq. In its IPO prospectus, the company says it has 5,700 reservations so far in the four months since it announced availability of its autonomous driving software for the rigs. When a truck is rolling at high speed, carrying a huge load of something, making sure the AI software safely conducts the vehicle is clearly a priority for society.

TuSimple says it has almost 6,000 pre-orders for a driverless semi-truck. When a truck is rolling at high speed, carrying a huge load of something, making sure the AI software safely conducts the vehicle is clearly a priority for society.
TuSimpleAnother area of concern is AI applied in the area of military and policing activities.
Arthur Holland Michel, author of an extensive book on military surveillance, Eyes in the Sky, has described how ImageNet has been used to enhance the U.S. military’s surveillance systems. For anyone who views surveillance as a useful tool to keep people safe, that is encouraging news. For anyone worried about the issues of surveillance unchecked by any civilian oversight, it is a disturbing expansion of AI applications.
Mass surveillance backlash
Calls are rising for mass surveillance, enabled by technology such as facial recognition, not to be used at all.
As ZDNet‘s Daphne Leprince-Ringuet reported last month, 51 organizations, including AlgorithmWatch and the European Digital Society, have sent a letter to the European Union urging a total ban on surveillance.
And it looks like there will be some curbs after all. After an extensive report on the risks a year ago, and a companion white paper, and solicitation of feedback from numerous “stakeholders,” the European Commission this month published its proposal for “Harmonised Rules On Artificial Intelligence For AI.” Among the provisos is a curtailment of law enforcement use of facial recognition in public.
“The use of ‘real time’ remote biometric identification systems in publicly accessible spaces for the purpose of law enforcement is also prohibited unless certain limited exceptions apply,” the report states.
The backlash against surveillance keeps finding new examples to which to point. The paradigmatic example had been the monitoring of ethic Uyghurs in China’s Xianxjang region. Following a February military coup in Myanmar, Human Rights Watch reports that human rights are in the balance given the surveillance system that had just been set up. That project, called Safe City, was deployed in the capital Naypidaw, in December.
As one researcher told Human Rights Watch, “Before the coup, Myanmar’s government tried to justify mass surveillance technologies in the name of fighting crime, but what it is doing is empowering an abusive military junta.”
Also: The US, China and the AI arms race: Cutting through the hype

The National Security Commission on AI’s Final Report in March warned the U.S. is not ready for global conflict that employs AI.
As if all those developments weren’t dramatic enough, AI has become an arms race, and nations have now made AI a matter of national policy to avoid what is presented as existential risk. The U.S.’s National Security Commission on AI, staffed by tech heavy hitters such as former Google CEO Eric Schmidt, Oracle CEO Safra Catz, and Amazon’s incoming CEO Andy Jassy, last month issued its 756-page “final report” for what it calls the “strategy for winning the artificial intelligence era.”
The authors “fear AI tools will be weapons of first resort in future conflicts,” they write, noting that “state adversaries are already using AI-enabled disinformation attacks to sow division in democracies and jar our sense of reality.”
The Commission’s overall message is that “The U.S. government is not prepared to defend the United States in the coming artificial intelligence era.” To get prepared, the White House needs to make AI a cabinet-level priority, and “establish the foundations for widespread integration of AI by 2025.” That includes “building a common digital infrastructure, developing a digitally-literate workforce, and instituting more agile acquisition, budget, and oversight processes.”
Reasons for ethical concern in the AI field
Why are these issues cropping up? There are issues of justice and authoritarianism that are timeless, but there are also new problems with the arrival of AI, and in particular its modern deep learning variant.
Consider the incident between Google and scholars Gebru and Mitchell. At the heart of the dispute was a research paper the two were preparing for a conference that crystallizes a questioning of the state of the art in AI.

The paper that touched off a controversy at Google: Gebru and Bender and Major and Mitchell argue that very large language models such as Google’s BERT present two dangers: massive energy consumption and perpetuating biases.
Bender et al.The paper, coauthored by Emily Bender of the University of Washington, Gebru, Angelina McMillan-Major, also of the University of Washington, and Mitchell, titled “On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?” focuses on a topic within machine learning called natural language processing, or NLP.
The authors describe how language models such as GPT-3 have gotten bigger and bigger, culminating in very large “pre-trained” language models, including Google’s Switch Transformer, also known as Switch-C, which appears to be the largest model published to date. Switch-C uses 1.6 trillion neural “weights,” or parameters, and is trained on a corpus of 745 gigabytes of text data.
The authors identify two risk factors. One is the environmental impact of larger and larger models such as Switch-C. Those models consume massive amounts of compute, and generate increasing amounts of carbon dioxide. The second issue is the replication of biases in the generation of text strings produced by the models.
The environment issue is one of the most vivid examples of the matter of scale. As ZDNet has reported, the state of the art in NLP, and, indeed, much of deep learning, is to keep using more and more GPU chips, from Nvidia and AMD, to operate ever-larger software programs. Accuracy of these models seems to increase, generally speaking, with size.
But there is an environmental cost. Bender and team cite previous research that has shown that training a large language model, a version of Google’s Transformer that is smaller than Switch-C, emitted 284 tons of carbon dioxide, which is 57 times as much CO2 as a human being is estimated to be responsible for releasing into the environment in a year.
It’s ironic, the authors note, that the ever-rising cost to the environment of such huge GPU farms impacts most immediately the communities on the forefront of risk from change whose dominant languages aren’t even accommodated by such language models, in particular the population of the Maldives archipelago in the Arabian Sea, whose official language is Dhivehi, a branch of the Indo-Aryan family:
Is it fair or just to ask, for example, that the residents of the Maldives (likely to be underwater by 2100) or the 800,000 people in Sudan affected by drastic floods pay the environmental price of training and deploying ever larger English LMs [language models], when similar large-scale models aren’t being produced for Dhivehi or Sudanese Arabic?
The second concern has to do with the tendency of these large language models to perpetuate biases that are contained in the training set data, which are often publicly available writing that is scraped from places such as Reddit. If that text contains biases, those biases will be captured and amplified in generated output.
The fundamental problem, again, is one of scale. The training sets are so large, the issues of bias in code cannot be properly documented, nor can they be properly curated to remove bias.
“Large [language models] encode and reinforce hegemonic biases, the harms that follow are most likely to fall on marginalized populations,” the authors write.
Ethics of compute efficiency
The risk of the huge cost of compute for ever-larger models has been a topic of debate for some time now. Part of the problem is that measures of performance, including energy consumption, are often cloaked in secrecy.
Some benchmark tests in AI computing are getting a little bit smarter. MLPerf, the main measure of performance of training and inference in neural networks, has been making efforts to provide more representative measures of AI systems for particular workloads. This month, the organization overseeing MLPerf, the MLCommons, for the first time asked vendors to list not just performance but energy consumed for those machine learning tasks.
Regardless of the data, the fact is systems are getting bigger and bigger in general. The response to the energy concern within the field has been two-fold: to build computers that are more efficient at processing the large models, and to develop algorithms that will compute deep learning in a more intelligent fashion than just throwing more computing at the problem.

Cerebras’s Wafer Scale Engine is the state of the art in AI computing, the world’s biggest chip, designed for the ever-increasing scale of things such as language models.
On the first score, a raft of startups have arisen to offer computers dedicate to AI that they say are much more efficient than the hundreds or thousands of GPUs from Nvidia or AMD typically required today.
They include Cerebras Systems, which has pioneered the world’s largest computer chip; Graphcore, the first company to offer a dedicated AI computing system, with its own novel chip architecture; and SambaNova Systems, which has received over a billion dollars in venture capital to sell both systems but also an AI-as-a-service offering.
“These really large models take huge numbers of GPUs just to hold the data,” Kunle Olukotun, Stanford University professor of computer science who is a co-founder of SambaNova, told ZDNet, referring to language models such as Google’s BERT.
“Fundamentally, if you can enable someone to train these models with a much smaller system, then you can train the model with less energy, and you would democratize the ability to play with these large models,” by involving more researchers, said Olukotun.
Those designing deep learning neural networks are simultaneously exploring ways the systems can be more efficient. For example, the Switch Transformer from Google, the very large language model that is referenced by Bender and team, can reach some optimal spot in its training with far fewer than its maximum 1.6 trillion parameters, author William Fedus and colleagues of Google state.
The software “is also an effective architecture at small scales as well as in regimes with thousands of cores and trillions of parameters,” they write.
The key, they write, is to use a property called sparsity, which prunes which of the weights get activated for each data sample.
Scientists at Rice University and Intel propose slimming down the computing budget of large neural networks by using a hashing table that selects the neural net activations for each input, a kind of pruning of the network.
Chen et al.Another approach to working smarter is a technique called hashing. That approach is embodied in a project called “Slide,” introduced last year by Beidi Chen of Rice University and collaborators at Intel. They use something called a hash table to identify individual neurons in a neural network that can be dispensed with, thereby reducing the overall compute budget.
Chen and team call this “selective sparsification”, and they demonstrate that running a neural network can be 3.5 times faster on a 44-core CPU than on an Nvidia Tesla V100 GPU.
As long as large companies such as Google and Amazon dominate deep learning in research and production, it is possible that “bigger is better” will dominate neural networks. If smaller, less resource-rich users take up deep learning in smaller facilities, than more-efficient algorithms could gain new followers.
AI ethics: A history of the recent past
The second issue, AI bias, runs in a direct line from the Bender et al. paper back to a paper in 2018 that touched off the current era in AI ethics, the paper that was the shot heard ’round the world, as they say.

Buolamwini and Gebru brought international attention to the matter of bias in AI with their 2018 paper “Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification,” which revealed that commercial facial recognition systems showed “substantial disparities in the accuracy of classifying darker females, lighter females, darker males, and lighter males in gender classification systems.”
Buolamwini et al. 2018That 2018 paper, “Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification,” was also authored by Gebru, then at Microsoft, along with MIT researcher Joy Buolamwini. They demonstrated how commercially available facial recognition systems had high accuracy when dealing with images of light-skinned men, but catastrophically bad inaccuracy when dealing with images of darker-skinned women. The authors’ critical question was why such inaccuracy was tolerated in commercial systems.
Buolamwini and Gebru presented their paper at the Association for Computing Machinery’s Conference on Fairness, Accountability, and Transparency. That is the same conference where in February Bender and team presented the Parrot paper. (Gebru is a co-founder of the conference.)
What is bias in AI?
Both Gender Shades and the Parrot paper deal with a central ethical concern in AI, the notion of bias. AI in its machine learning form makes extensive use of principles of statistics. In statistics, bias is when an estimation of something turns out not to match the true quantity of that thing.
So, for example, if a political pollster takes a poll of voters’ preferences, if they only get responses from people who talk to poll takers, they may get what is called response bias, in which their estimation of the preference for a certain candidate’s popularity is not an accurate reflection of preference in the broader population.
Also: AI and ethics: One-third of executives are not aware of potential AI bias
The Gender Shades paper in 2018 broke ground in showing how an algorithm, in this case facial recognition, can be extremely out of alignment with the truth, a form of bias that hits one particular sub-group of the population.
Flash forward, and the Parrot paper shows how that statistical bias has become exacerbated by scale effects in two particular ways. One way is that data sets have proliferated, and increased in scale, obscuring their composition. Such obscurity can obfuscate how the data may already be biased versus the truth.
Second, NLP programs such as GPT-3 are generative, meaning that they are flooding the world with an amazing amount of created technological artifacts such as automatically generated writing. By creating such artifacts, biases can be replicated, and amplified in the process, thereby proliferating such biases.
Questioning the provenance of AI data
On the first score, the scale of data sets, scholars have argued for going beyond merely tweaking a machine learning system in order to mitigate bias, and to instead investigate the data sets used to train such models, in order to explore biases that are in the data itself.
Before she was fired from Google’s Ethical AI team, Mitchell lead her team to develop a system called “Model Cards” to excavate biases hidden in data sets. Each model card would report metrics for a given neural network model, such as looking at an algorithm for automatically finding “smiling photos” and reporting its rate of false positives and other measures.
Mitchell et al.One example is an approach created by Mitchell and team at Google called model cards. As explained in the introductory paper, “Model cards for model reporting,” data sets need to be regarded as infrastructure. Doing so will expose the “conditions of their creation,” which is often obscured. The research suggests treating data sets as a matter of “goal-driven engineering,” and asking critical questions such as whether data sets can be trusted and whether they build in biases.
Another example is a paper last year, featured in The State of AI Ethics, by Emily Denton and colleagues at Google, “Bringing the People Back In,” in which they propose what they call a genealogy of data, with the goal “to investigate how and why these datasets have been created, what and whose values influence the choices of data to collect, the contextual and contingent conditions of their creation, and the emergence of current norms and standards of data practice.”
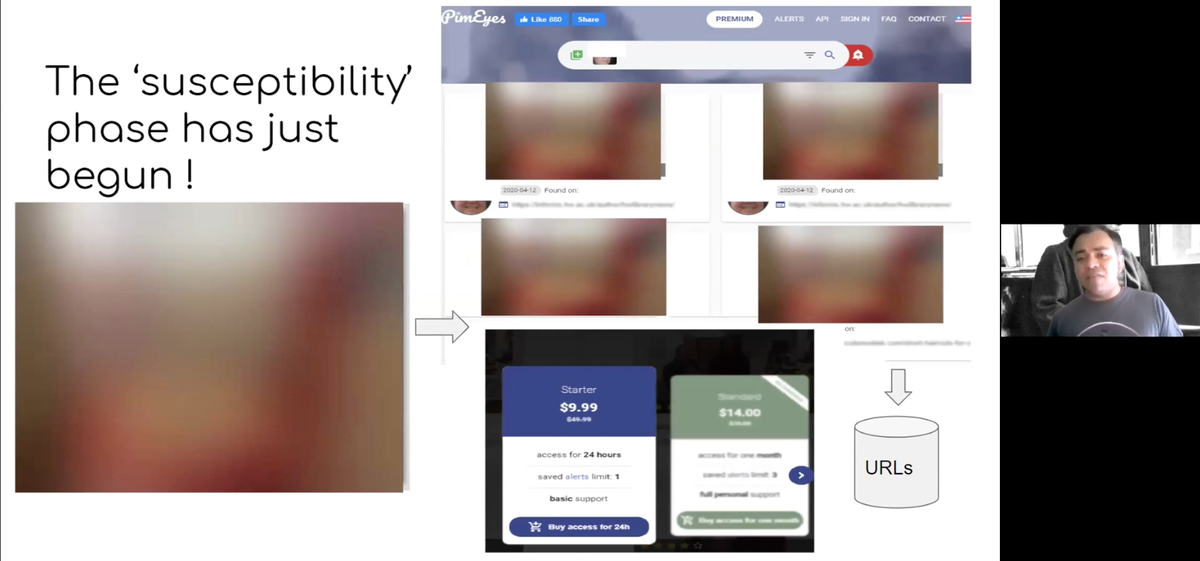
Vinay Prabhu, chief scientist at UnifyID, in a talk at Stanford last year described being able to take images of people from ImageNet, feed them to a search engine, and find out who people are in the real world. It is the “susceptibility phase” of data sets, he argues, when people can be targeted by having had their images appropriated.
Prabhu 2020Scholars have already shed light on the murky circumstances of some of the most prominent data sets used in the dominant NLP models. For example, Vinay Uday Prabhu, who is chief scientist at startup UnifyID Inc., in a virtual talk at Stanford University last year examined the ImageNet data set, a collection of 15 million images that have been labeled with descriptions.
The introduction of ImageNet in 2009 arguably set in motion the deep learning epoch. There are problems, however, with ImageNet, particularly the fact that it appropriated personal photos from Flickr without consent, Prabhu explained.
Those non-consensual pictures, said Prabhu, fall into the hands of thousands of entities all over the world, and that leads to a very real personal risk, he said, what he called the “susceptibility phase,” a massive invasion of privacy.
Using what’s called reverse image search, via a commercial online service, Prabhu was able to take ImageNet pictures of people and “very easily figure out who they were in the real world.” Companies such as Clearview, said Prabhu, are merely a symptom of that broader problem of a kind-of industrialized invasion of privacy.
An ambitious project has sought to catalog that misappropriation. Called Exposing.ai, it is the work of Adam Harvey and Jules LaPlace, and it formally debuted in January. The authors have spent years tracing how personal photos were appropriated without consent for use in machine learning training sets.
The site is a search engine where one can “check if your Flickr photos were used in dozens of the most widely used and cited public face and biometric image datasets […] to train, test, or enhance artificial intelligence surveillance technologies for use in academic, commercial, or defense related applications,” as Harvey and LaPlace describe it.
The dark side of data collection
Some argue the issue goes beyond simply the contents of the data to the means of its production. Amazon’s Mechanical Turk service is ubiquitous as a means of employing humans to prepare vast data sets, such as by applying labels to pictures for ImageNet or to rate chat bot conversations.
An article last month by Vice‘s Aliide Naylor quoted Mechanical Turk workers who felt coerced in some instances to produce results in line with a predetermined objective.
The Turkopticon feedback aims to arm workers on Amazon’s Mechanical Turk with honest appraisals of the work conditions of contracting for various Turk clients.
TurkopticonA project called Turkopticon has arisen to crowd-source reviews of the parties who contract with Mechanical Turk, to help Turk workers avoid abusive or shady clients. It is one attempt to ameliorate what many see as the troubling plight of an expanding underclass of piece workers, what Mary Gray and Siddharth Suri of Microsoft have termed “ghost work.”
There are small signs the message of data set concern has gotten through to large organizations practicing deep learning. Facebook this month announced a new data set that was created not by appropriating personal images but rather by making original videos of over three thousand paid actors who gave consent to appear in the videos.
The paper by lead author Caner Hazirbas and colleagues explains that the “Casual Conversations” data set is distinguished by the fact that “age and gender annotations are provided by the subjects themselves.” Skin type of each person was annotated by the authors using the so-called Fitzpatrick Scale, the same measure that Buolamwini and Gebru used in their Gender Shades paper. In fact, Hazirbas and team prominently cite Gender Shades as precedent.
Hazirbas and colleagues found that, among other things, when machine learning systems are tested against this new data set, some of the same failures crop up as identified by Buolamwini and Gebru. “We noticed an obvious algorithmic bias towards lighter skinned subjects,” they write.
Aside from the results, one of the most telling lines in the paper is a potential change in attitude to approaching research, a humanist streak amidst the engineering.
“We prefer this human-centered approach and believe it allows our data to have a relatively unbiased view of age and gender,” write Hazirbas and team.

Facebook’s Casual Conversations data set, released in April, puports to be a more honest way to use likenesses for AI training. The company paid actors to model for videos and scored their complexion based on a dermotological scale.
Hazirbas et al.Another intriguing development is the decision by the MLCommons, the industry consortium that creates the MLPerf benchmark, to create a new data set for use in speech-to-text, the task of converting a human voice into a string of automatically generated text.
The data set, The People’s Speech, contains 87,000 hours of spoken verbiage. It is meant to train audio assistants such as Amazon’s Alexa. The point of the data set is that it is offered under an open-source license, and it is meant to be diverse: it contains speech in 59 languages.
The group claims, “With People’s Speech, MLCommons will create opportunities to extend the reach of advanced speech technologies to many more languages and help to offer the benefits of speech assistance to the entire world population rather than confining it to speakers of the most common languages.”
Generative everything: The rise of the fake
The ethical issues of bias are amplified by that second factor identified by the Parrot paper, the fact that neural networks are more and more “generative,” meaning, they are not merely acting as decision-making tools, such as a classic linear regression machine learning program. They are flooding the world with creations.
The classic example is “StyleGAN,” introduced in 2018 by Nvidia and made available on Github. The software can be used to generate realistic faces: It has spawned an era of fake likenesses.
Stanford’s AI Index Report, released in March, gives an annual rundown of the state of play in various aspects of AI. The latest edition describes what it calls “generative everything,” the prevalence of these new digital artifacts.
“AI systems can now compose text, audio, and images to a sufficiently high standard that humans have a hard time telling the difference between synthetic and non-synthetic outputs for some constrained applications of the technology,” the report notes.
“That promises to generate a tremendous range of downstream applications of AI for both socially useful and less useful purposes.”

None of these people are real. Tero Karras and colleagues in 2019 stunned the world with surprisingly slick fake likenesses, which they created with a new algorithm they called a style-based generator architecture for generative adversarial networks, or StyleGAN.
Credit: Kerras et al. 2019The potential harms of generative AI are numerous.
There is the propagation of text that recapitulates societal biases, as pointed out by the Parrot paper. But there are other kinds of biases that can be created by the algorithms that act on that data. That includes, for example, algorithms whose goal is to classify human faces into categories of “attractiveness” or “unattractiveness.” So-called generative algorithms, such as GANs, can be used to endlessly reproduce a narrow formulation of what is purportedly attractive in order to flood the world with that particular aesthetic to the exclusion of all else.
By appropriating data and re-shaping it, GANs raise all kinds of new ethical questions of authorship and responsibility and credit. Generative artworks have been auctioned for large sums of money. But whose works are they? If they appropriate existing material, as is the case in many GAN machines, then who is supposed to get credit? Is it the engineer who built the algorithm, or the human artists whose work was used to train the algorithm?
There is also the DeepFake wave, where fake images and fake recordings and fake text and fake videos can mislead people about the circumstances of events.

This person does not exist, it is made via software derived from StyleGAN.
ThispersondoesnotexistAnd an emerging area is the concocting of fake identities. Using sites such as thispersondoesnotexist.com, built from the StyleGAN code, people can concoct convincing visages that are an amalgamation of features. Researcher Rumman Chowdhury of Twitter has remarked that such false faces can be utilized for fake social accounts that are then a tool with which people can harass others on social media.
Venture capitalist Konstantine Buehler with Sequoia Capital has opined that invented personas, perhaps like avatars, will increasingly become a normal part of people’s online engagement.
Fake personalities, DeepFakes, amplified biases, appropriation without credit, beauty contests — all of these generative developments are of a piece. They are the rapid spread of digital artifacts with almost no oversight or discussion of the ramifications.
Classifying AI risks
A central challenge of AI ethics is simply to define the problem correctly. A substantial amount of organized, formal scholarship has been devoted in recent years to the matter of determining the scope and breadth of ethical issues.
For example, the non-profit Future of Life gave $2 million in grants to ten research projects on that topic in 2018, funded by Elon Musk. There have been tons of reports and proposals produced by institutions in the past few years. And AI Ethics is now an executive role at numerous corporations.
Numerous annual reports seek to categorize or cluster ethical issues. A study of AI by Capgemini published last October, “AI and the Ethical Conundrum,” identified four vectors of ethics in machine learning: explainability, fairness, transparency, and auditability, meaning, and the ability to audit a machine learning system to determine how it functions.
According to Capgemini, only explainability had shown any progress from 2019 to 2020, while the other three were found to be “underpowered” or had “failed to evolve.”
Also: AI and ethics: One-third of executives are not aware of potential AI bias
A very useful wide-ranging summary of the many issues in AI ethics is provided in a January report, “The State of AI Ethics,” by the non-profit group The Montreal AI Ethics Institute. The research publication gathers numerous original scholarly papers, and also media coverage, summarizes them, and organizes them by issue.
The takeaway from the report is that issues of ethics cover a much wider spectrum than one might think. They include algorithmic injustice, discrimination, labor impacts, misinformation, privacy, and risk and security.
Trying to measure ethics
According to some scholars who’ve spent time poring over data on ethics, a key limiting factor is that there isn’t enough quantitative data.
That was one of the conclusions offered last month in the fourth annual AI Index, put out by HAI, the Human-Centered AI institute at Stanford University. In its chapter devoted to ethics, the scholars noted they were “surprised to discover how little data there is on this topic.”
“Though a number of groups are producing a range of qualitative or normative outputs in the AI ethics domain,” the authors write, “the field generally lacks benchmarks that can be used to measure or assess the relationship between broader societal discussions about technology development and the development of the technology itself.”

Stanford University’s Human-Centered AI group annually produces the AI Index Report, a roundup of the most significant trends in AI, including ethics concerns.
Stanford HAIAttempts to measure ethics raise questions about what one is trying to measure. Take the matter of bias. It sounds simple enough to say that the answer to bias is to correct a statistical distribution to achieve greater “fairness.” Some have suggested that is too simplistic an approach.
Among Mitchell’s projects when she was at Google was to move the boundaries of discussion of bias beyond issues of fairness, and meaning, questioning what balance in data sets would mean for different populations in the context of justice.
In a work last year, “Diversity and Inclusion Metrics in Subset Selection,” Mitchell and team applied set theory to create a quantifiable framework for whether a given algorithm increases or decreases the amount of “diversity” and “inclusion.” Those terms go beyond how much a particular group in society is represented to instead measure the degree of presence of attributes in a group, along lines of gender or age, say.
Using that approach, one can start to do things such as measure a given data set for how much it fulfills “ethical goals” of, say, egalitarianism, that would “favor under-served individuals that share an attribute.”
Establishing a code of ethics
A number of institutions have declared themselves in favor of being ethical in one form or another, though the benefit of those declarations is a matter of debate.
One of the most famous statements of principle is the 2018 Montreal Declaration on Responsible AI, from the University of Montreal. That declaration frames many high-minded goals, such as autonomy for human beings, and protection of individual privacy.

The University of Montreal’s Montreal Declaration is one of the most well-known statements of principle on AI.
Institutions declaring some form of position on AI ethics include top tech firms such as IBM, SAP, Microsoft, Intel, and Baidu; government bodies such as the U.K. House of Lords; non-governmental institutions such as The Vatican; prestigious technical organizations such as the IEEE; and specially-formed bodies such as the European Commission’s European Group on Ethics in Science and New Technologies.
A list of which institutions have declared themselves in favor of ethics in the field since 2015 has been compiled by research firm The AI Ethics Lab. At last count, the list totaled 117 organizations. The AI Index from Stanford’s HAI references the Lab’s work.
It’s not clear that all those declarations mean much at this point. A study by the AI Ethics Lab published in December, in the prestigious journal Communications of the ACM, concluded that all the deep thinking by those organizations couldn’t really be put into practice.
As Cansu Canca, director of the Lab, wrote, the numerous declarations were “mostly vaguely formulated principles.” More important, they confounded, wrote Canca, two kinds of ethical principles, what are known as core, and what are known as instrumental.
Drawing on longstanding work in bioethics, Canca proposes that ethics of AI should start with three core principles, namely, autonomy; the cost-benefit tradeoff; and justice. Those are “values that theories in moral and political philosophy argue to be intrinsically valuable, meaning their value is not derived from something else,” wrote Canca.
How do you operationalize ethics in AI?
Everything else in the ethics of AI, writes Canca, would be instrumental, meaning, only important to the extent that it guarantees the core principles. So, transparency, for example, such as transparency of an AI model’s operation, or explainability, would be important not in and of itself, but to the extent that it is “instrumental to uphold intrinsic values of human autonomy and justice.”
The focus on operationalizing AI is becoming a trend. A book currently in press by Abhishek Gupta of Microsoft, Actionable AI Ethics, due out later this year, also takes up the theme of operationalization. Gupta is the founder of the Montreal AI Ethics Institute.
Abhishek claims the book will recover the signal from the noise in the “fragmented tooling and framework landscape in AI ethics.” The book promises to help organizations “evoke a high degree of trust from their customers in the products and services that they build.”
In a similar vein, Ryan Calo, a professor of law at University of Washington, stated during the AI Debate 2 in December that principles are problematic because they “are not self-enforcing,” as “there are no penalties attached to violating them.”
“Principles are largely meaningless because in practice they are designed to make claims no one disputes,” said Caro. “Does anyone think AI should be unsafe?”
Instead, “What we need to do is roll up our sleeves and assess how AI affects human affordances, and then adjust our system of laws to this change.
“Just because AI can’t be regulated as such, doesn’t mean we can’t change law in response to it.”
Whose algorithm is it, anyway?
AI, as any tool in the hands of humans, can do harm, as one-time world chess champion Gary Kasparov has written.
“An algorithm that produces biased results or a drone that kills innocents is not acting with agency or purpose; they are machines doing our bidding as clearly as a hand wielding a hammer or a gun,” writes Kasparov in his 2017 book, Deep Thinking: Where machine intelligence ends and human creativity begins.
The cutting-edge of scholarship in the field of AI ethics goes a step farther. It asks what human institutions are the source of those biased and dangerous implements.
Some of that scholarship is finally finding its way into policy and, more important, operations. Twitter this month announced what it calls “responsible machine learning,” under the direction of data scientist Chowdhury and product manager Jutta Williams. The duo write in their inaugural post on the topic that the goal at Twitter will be not just to achieve some “explainable” AI, but also what they call “algorithmic choice.”
“Algorithmic choice will allow people to have more input and control in shaping what they want Twitter to be for them,” the duo write. “We’re currently in the early stages of exploring this and will share more soon.”
AI: Too narrow a field?
The ethics effort is pushing up against the limitations of a computer science discipline that, some say, cares too little about other fields of knowledge, including the kinds of deep philosophical questions raised by Marcel.
In a paper published last month by Inioluwa Deborah Raji of the Mozilla Foundation and collaborators, “You Can’t Sit With Us: Exclusionary Pedagogy in AI Ethics Education,” the researchers analyzed over 100 syllabi used to teach AI ethics at the University Level. Their conclusion is that efforts to insert ethics into computer science with a “sprinkle of ethics and social science” won’t lead to meaningful change in how such algorithms are created and deployed.
The discipline is in fact growing more insular, Raji and collaborators write, by seeking purely technical fixes to the problem and refusing to integrate what has been learned in the social sciences and other humanistic fields of study.
“A discipline which has otherwise been criticized for its lack of ethical engagement is now taking up the mantle of instilling ethical wisdom to its next generation of students,” is how Raji and team characterize the situation.
Evolution of AI with digital consciousness
The risk of scale discussed in this guide leaves aside a vast terrain of AI exploration, the prospect of an intelligence that humans might acknowledge is human-like. The term for that is artificial general intelligence, or AGI.
Such an intelligence raises dual concerns. What if such an intelligence sought to advance its interests at the price of human interests? Conversely, what moral obligation do humans have to respect the rights of such an intelligence in the same way as human rights must be regarded?
AGI today is mainly the province of philosophical inquiry. Conventional wisdom is that AGI is many decades off, if it can ever be achieved. Hence, the rumination tends to be highly speculative and wide-ranging.
At the same time, some have argued that it is precisely the lack of AGI that is one of the main reasons that bias and other ills of conventional AI are so prevalent. The Parrot paper by Bender et al. asserts that the issue of ethics ultimately comes back to the shallow quality of machine learning, its tendency to capture the statistical properties of natural language form without any real “understanding.”

Gary Marcus and Ernest Davis argue in their book Rebotting AI that the lack of common sense in the machine learning programs is one of the biggest factors in the potential harm from the programs.
That view echoes concerns by both practitioners of machine learning and its critics.
NYU psychology professor and AI entrepreneur Gary Marcus, one of the most vocal critics of machine learning, argues that no engineered system that impacts human life can be trusted if it hasn’t been developed with a human-level capacity for common sense. Marcus explores that argument in extensive detail in his 2019 book Rebooting AI, written with colleague Ernest Davis.
During AI Debate 2, organized by Marcus in December, scholars discussed how the shallow quality of machine learning can perpetuate biases. Celeste Kidd, the UC Berkeley professor, remarked that AI systems for content recommendation, such as on social networks, can push people toward “stronger, inaccurate beliefs that despite our best efforts are very difficult to correct.”
“Biases in AI systems reinforce and strengthen bias in the people that use them,” said Kidd.
AI for good: What is possible?
Despite the risks, a strong countervailing trend in AI is the belief that artificial intelligence can help solve some of society’s biggest problems.
Tim O’Reilly, the publisher of technical books used by multiple generations of programmers, believes problems such as climate change are too big to be solved without some use of AI.
Despite AI’s dangers, the answer is more AI, he thinks, not less. “Let me put it this way, the problems we face as a society are so large, we are going to need all the help we can get,” O’Reilly has told ZDNet. “The way through is forward.”
Expressing the dichotomy of good and bad effects, Steven Mills, who oversees ethics of AI for the Boston Consulting Group, writes in the preface to The State of AI Ethics that artificial intelligence has a dual nature:
AI can amplify the spread of fake news, but it can also help humans identify and filter it; algorithms can perpetuate systemic societal biases, but they can also reveal unfair decision processes; training complex models can have a significant carbon footprint, but AI can optimize energy production and data center operations.
AI to find biases
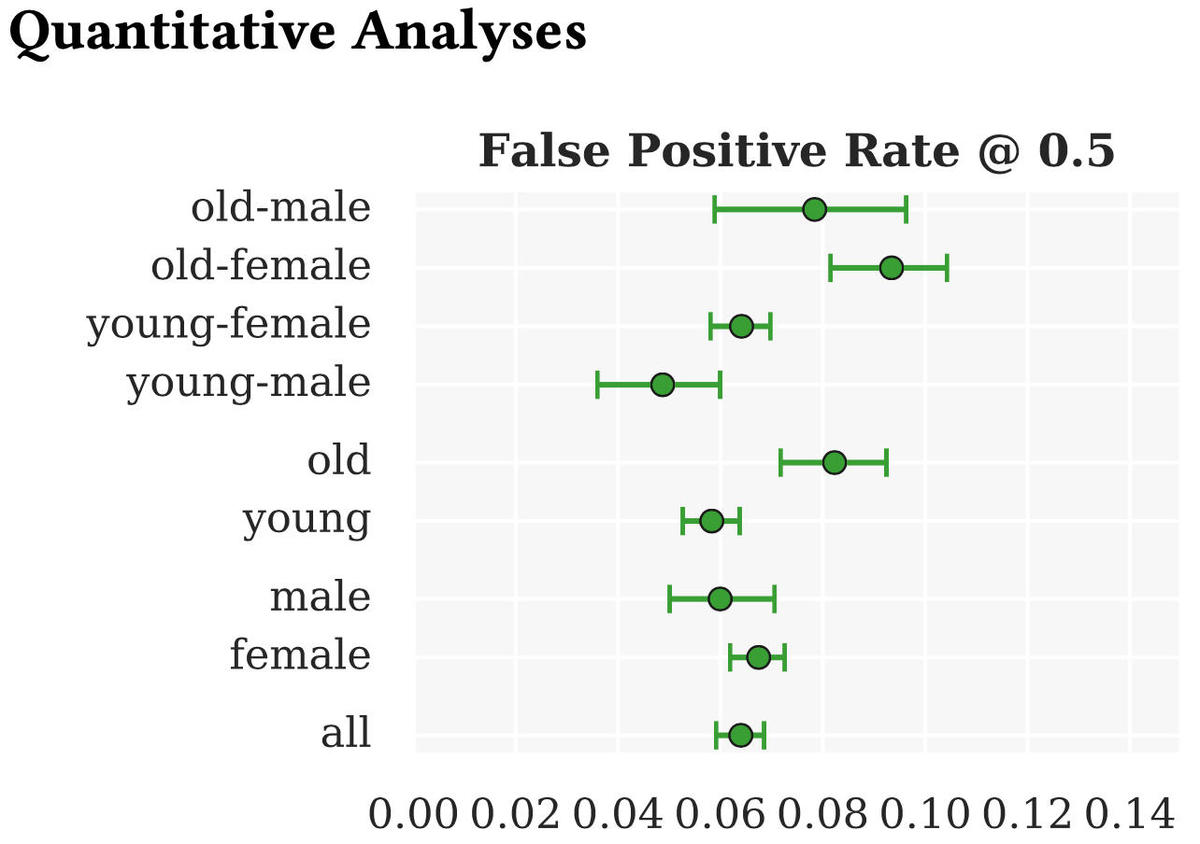
An example of AI turned to potential good is using machine learning to uncover biases. One such study was a November cover story in the journal Nature about an experiment conducted by Dominik Hangartner and colleagues at ETH Zurich and The London School of Economics. The authors examined clicks on job applicant listings on a website by recruiters in Switzerland. They demonstrated that ethnicity and gender had a significant negative affect on the likelihood of job offers, with the inequity reducing the chances for women and people from minority ethnic groups.
The study is interesting because its statistical findings were only possible because of new machine learning tools developed in the past decade.
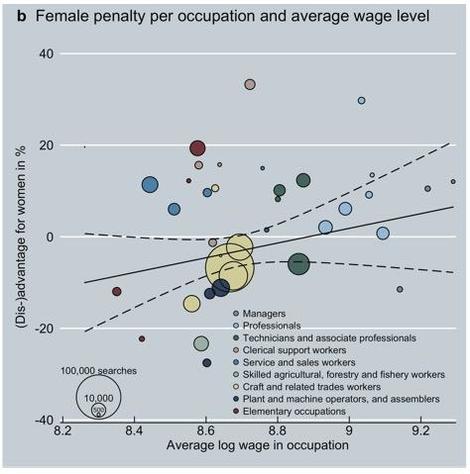
Hangartner and colleagues at ETH Zurich and the London School of Economics used novel machine learning techniques to isolate biases that lead to discrimination by recuiters when reviewing online applications.
Hangartner et al.In order to control for the non-ethnicity and non-gender attributes, the work made use of a method developed by Alexandre Belloni of Duke University and colleagues that figures out the relevant attributes to be measured based on the data, rather than specifying it beforehand. The statistical model gets more powerful in its measurement the more that it is exposed to data, which is the essence of machine learning.
Progress in AI-driven autonomous vehicles
One broad category of potential that defenders of industrial AI like to point to is reducing accidents via autonomous vehicles that use some form of advanced driver-assistance system, or ADAS. These are varying levels of automatic maneuvers including automatic acceleration or braking of a vehicle, or lane changing.
The jury is still out on how much safety is improved. During a conference organized last year by the Society of Automotive Engineers, data was presented on 120 drivers during a total of 216,585 miles in ten separate vehicles using what the Society has defined as “Level 2” of ADAS, in which a human must continue to observe the road while the computer makes the automated maneuvers.
At the meeting, a representative of the Insurance Institute for Highway Safety, David Zuby, after reviewing the insurance claims data, said that “the Level-2 systems in the vehicles studied might – emphasis on ‘might’ – be associated with a lower frequency of crash claims against insurance coverage.”
Determining the positives of autonomous driving is made more complicated by tug of war between industry and regulators. Tesla’s Musk has taken to tweeting about the safety of his company’s vehicles, often second-guessing official investigations.
This month, as investigators were looking into the matter of a Tesla Model S sedan in Texas that failed to negotiate a curve, hit a tree, and burst into flames, killing the two people inside the car, Musk tweeted what his company found from the data logs before investigators had a chance to look at those logs, as Reuters reported.
Tesla with Autopilot engaged now approaching 10 times lower chance of accident than average vehicle https://t.co/6lGy52wVhC
— Elon Musk (@elonmusk) April 17, 2021
TuSimple, the autonomous truck technology company, focuses on making trucks drive only predefined routes between an origin and a destination terminal. In its IPO prospectus, the company argues that such predefined routes will reduce the number of “edge cases,” unusual events that can lead to safety issues.
TuSimple is building Level 4 ADAS, where the truck can move without having a human driver in the cab.
AI for advancing drug discovery
An area of machine learning that may reach meaningful achievement before automation is the area of drug discovery. Another young company going public, Recursion Pharmaceuticals, has pioneered using machine learning to infer relationships between drug compounds and biological targets, which it claims can drastically expand the universe of compound and target combinations that can be searched.
Recursion has yet to produce a winner, nor have any software firms in pharma, but it’s possible there may be concrete results from clinical trials in the next year or so. The company has 37 drug programs in its pipeline, of which 4 are in Phase 2 clinical trials, which is the second of three stages, when efficacy is determined against a disease.
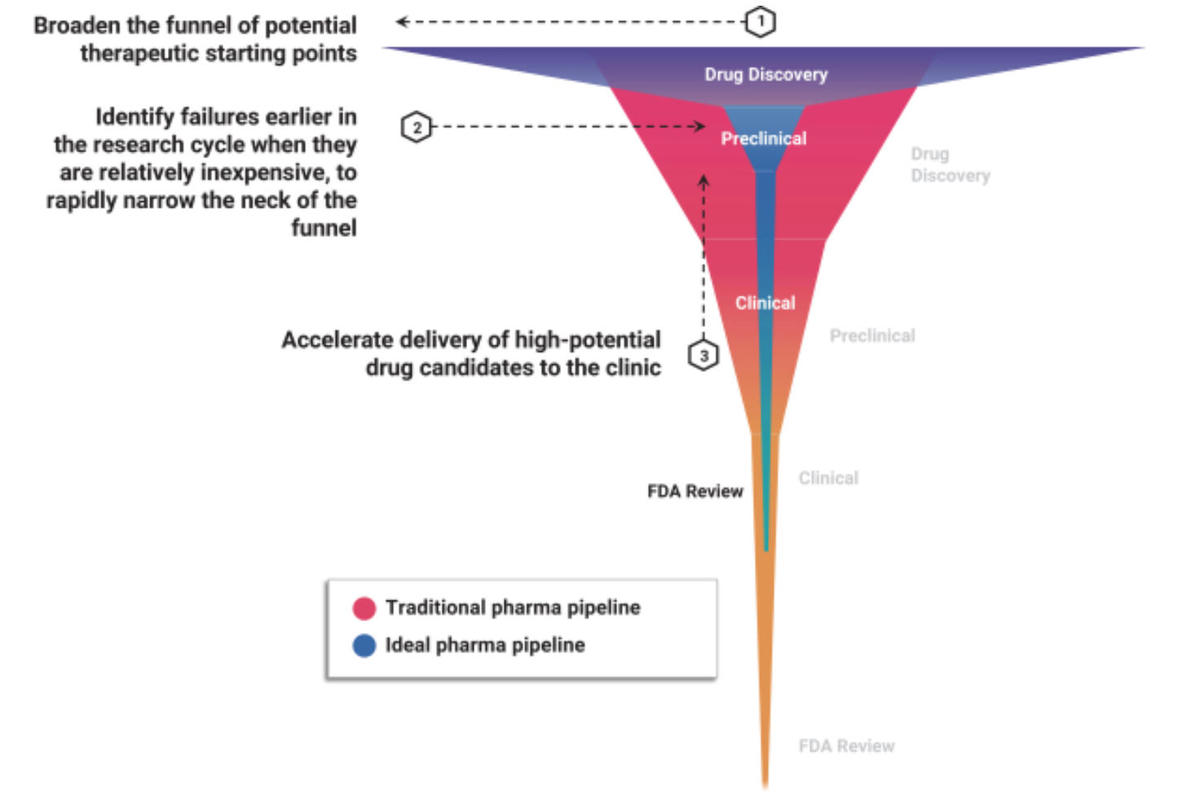
Salt Lake City startup Recursion Pharmceuticals, which has gone public on Nasdaq under the ticker “RXRX,” says it can use machine learning to make an “ideal pharma pipeline.”
Recursion PharmaceuticalsThe work of companies such as Recursion has two-fold appeal. First, AI may find novel compounds, chemical combinations no lab scientist would have come to, or not with as great a likelihood.
Also: The subtle art of really big data: Recursion Pharma maps the body
Second, the vast library of thousands of compounds, and thousands of drugs already developed, and in some cases even tested and marketed, can be re-directed to novel use cases if AI can predict how they will fare against diseases for which they were never indicated before.
This new mechanism of so-called drug repurposing, re-using what has already been explored and developed at tremendous cost, could make it economical to find cures for orphan diseases, conditions where the market is usually too small to attract original investment dollars by the pharmaceutical industry.
Other applications of AI in drug development include assuring greater coverage for subs-groups of the population. For example, MIT scientists last year developed machine learning models to predict how well COVID-19 vaccines would cover people of white, Black and Asian genetic ancestry. That study found that “on average, people of Black or Asian ancestry could have a slightly increased risk of vaccine ineffectiveness” when administered Moderna, Pfizer and AstraZeneca vaccines.
AI is just getting started on climate change
An area where AI scholars are actively doing extensive research is in climate change.
The organization Climate Change AI, a group of volunteer researchers from institutions around the world, in December of 2019 presented 52 papers exploring numerous aspects of how AI can have an impact on climate change, including real-time weather predictions, making buildings more energy-efficient, and using machine learning to design better materials for solar panels.
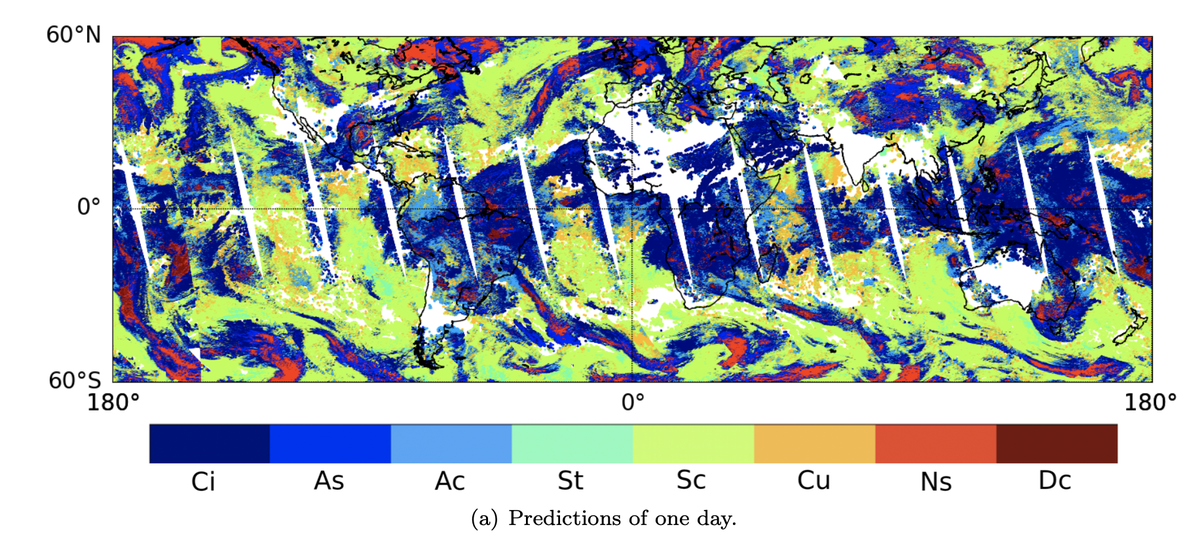
Much climate work in AI circles is at a basic research stage. An example is a project by GE and the Georgia Institute of Technology, called “Cumulo,” which can ingest pictures of clouds at 1 kilometer in resolution and, going pixel by pixel, categorize what type of cloud it is. Types of clouds in the world affect climate models, so you can’t actually model climate with great accuracy without knowing about which types are present and to what extent.
Zantedeschi et al.A lot of the AI work on climate at this point in time has the quality of laying the groundwork for years of research. It’s not yet clear whether the optimizations that come out of that scholarship will lead to emissions reduction, or how quickly.
When good intentions fail in AI
An important element of AI in the world is that it can fall afoul of best practices that have already been established in a given field of endeavor.
A good example is the quest to apply AI to detecting COVID-19. In early 2020, when tests for COVID-19 based on real-time polymerase chain reaction kits (RT-PCR) were in short supply globally, AI scientists in China and elsewhere worked with radiologists to try to apply machine learning to automatically examining chest x-rays and radiographs, as a way to speed up COVID-19. (A chest X-ray or radiograph can show ground-glass opacities, a telltale sign of the disease.)
But shortcomings in AI with respect to established best practices in the field of medical research, and statistical research, mean that most of those efforts have come to naught, according to a research paper in the journal Nature Machine Intelligence last month authored by Michael Roberts of Cambridge University and colleagues.
Of all the many machine learning programs created for the task, “none are currently ready to be deployed clinically,” the authors found, a staggering loss for a promising technology.
Also: AI runs smack up against a big data problem in COVID-19 diagnosis
To figure out why, the scientists looked at two thousand papers in the literature from last year, and finally narrowed it down to a survey of sixty-two papers that met various research criteria. They found that “Many studies are hampered by issues with poor-quality data, poor application of machine learning methodology, poor reproducibility and biases in study design.”
Among recommendations, the authors suggest not relying on “Frankenstein data sets” cobbled together from public repositories, an admonition that echoes the concerns by Gebru and Mitchell and others regarding data sets.
The authors also recommend a much more robust approach to validating programs, such as making sure training data for machine learning doesn’t slip into the validation data set. There were also certain best practices of reproducible research that were not followed. For example, “By far the most common point leading to exclusion was failure to state the data pre-processing techniques in sufficient detail.”
The greatest threat is AI illiteracy
Perhaps the greatest ethical issue is one that has received the least treatment from academics and corporations: Most people have no idea what AI really is. The public at large is AI ignorant, if you will.
The ignorance is partly a consequence of what has been termed sycophantic journalism, hawking unexamined claims by corporations about what AI can do. But ignorance on the part of journalists is also reflective of the broader societal ignorance.
The companion article to this article, AI in sixty seconds, attempts to provide some basic understanding to those who have absolutely no familiarity with the technology.
Also: Why is AI reporting so bad?
Attempts to deal with that knowledge gap have so far focused on myth-busting. Scholars over at the Mozilla dot org foundation last year introduced an effort to debunk nonsense about artificial intelligence, called AI myths.

Read: AI in sixty seconds
Myth busting, or its cousin, ignorance shaming, don’t seem to have gotten wide currency at this point. There have been calls for formal instruction in AI at an early age, but people need literacy at all ages because with intellectual maturity come varying levels of understanding.
There are practical demonstrations that can actually help a grown adult to visualize issues of algorithmic bias, for example. A Google team called People + AI Research have produced interactive demonstrations that let one get a feel for how bias emerges in the way that photos are selected in response to a query about CEOs or doctors. The photos optimizing along one narrow path by selecting the abundance of, say, white male images of CEOs and Doctors in the data set is one of the risks that can be visually conveyed.
Also: What is AI? Everything you need to know about Artificial Intelligence
Such studies can start to bring the public a more tangible understanding of the nature of algorithms. What is still lacking is an understanding of the broad sweep of a set of technologies that transform input into output.
An MIT project last year, led by PhD candidate Ziv Epstein, sought to understand why the public has terrible notions about AI, especially the anthropomorphic presumptions that ascribe consciousness to deep learning programs where no consciousness in fact exists.
Epstein’s suggestion is to give more people hands-on experience with the tools of machine learning.
“The best way to learn about something is to get really tangible and tactile with it, to play with it yourself,” Epstein told ZDNet. “I feel that’s the best way to get not only an intellectual understanding but also an intuitive understanding of how these technologies work and dispel the illusions.”
What kind of objective function does society want?
Looking at what a machine is and how it operates can reveal what things needs to be thought about more deeply.
Yoshua Bengio of Montreal’s MILA institute for AI, a pioneer of deep learning, has described deep learning programs as being composed of three things: an architecture, meaning, the way that artificial neurons are combined; a learning rule, meaning the way that weights of a neural network are corrected to improve performance, such as stochastic gradient descent; and an objective function. There is the data, which you could think of as a fourth element, if you like.
Also: What’s in a name? The ‘deep learning’ debate
Much of today’s work is focusing on the data, and there has been scrutiny of the scale of architectures, as in the Parrot paper, but the objective function may be the final frontier of ethics.
The objective function, also known as a loss function, is the thing one is trying to optimize. It can be viewed in purely technical terms as a mathematical measure. Oftentimes, however, the objective function is designed to reflect priorities that must themselves be investigated.
Mathematician Cathy O’Neil has labeled many statistics-driven approaches to optimizing things as “Weapons of Math Destruction,” the title of her 2016 book about how algorithms are misused throughout society.
The central problem is one of exclusion, O’Neil explains. Algorithms can force an objective function that is so narrow that it prioritizes one thing to the exclusion of all else. “Instead of searching for the truth, the score comes to embody it,” writes O’Neil.
A convolutional neural network whose objective function is to output a score of how “beautiful’ a given photograph of a face is.
Xu et al.The example comes to mind of GANs whose loss function is to create the “most attractive” fake picture of a person. Why, one may ask, are tools being devoted to create the most attractive anything?
A classic example of a misplaced objective function is the use of machine learning for emotion detection. The programs are supposed to be able to classify the emotional state of a person based on image recognition that identifies facial expressions and has been trained to link those to labels of emotion such as fear and anger.
But psychologist Lisa Feldman Barrett has criticized the science underlying such a scheme. Emotion recognition systems are not trained to detect emotions, which are complex, nuanced systems of signs, but rather to lump various muscle movements into predetermined bins labeled as this or that emotion.
The neural net is merely recreating the rather crude and somewhat suspect reductive categorization upon which it was based.
The objective function, then, is a thing that is the product of various notions, concepts, formulations, attitudes, etc. Those could be researchers’ individual priorities, or they could be a corporation’s priorities. The objective function must be examined and questioned.
Research from Gebru and Mitchell and other scholars is pressing against those objective functions, even as the industrialization of the technology, via firms such as Clearview, rapidly multiplies the number of objective functions that are being instituted in practice.
At the Climate Change AI meeting in December of 2019, MILA’s Bengio was asked how AI as a discipline can incentivize work on climate change.
“Change your objective function,” Bengio replied. “The sort of projects we’re talking about in this workshop can potentially be much more impactful than one more incremental improvement in GANs, or something,” he said.
Also: Stuart Russell: Will we choose the right objective for AI before it destroys us all?

Stanford University researcher Stuart Russell argues humans need to start thinking now about how they will tell tomorrow’s powerful AI to follow goals that are “human-compatible.”
Stuart RussellSome say the potential for AGI some day means society needs to get straight its objective function now.
Stuart Russell, professor of artificial intelligence at the University of California at Berkeley, has remarked that “If we are building machines that make decisions better than we can, we better be making sure they make decisions in our interest.”
To do so, humans need to be building machines that are intelligent not so much in fulfilling an arbitrary objective, but rather humanity’s objective.
“What we want are machines that are beneficial to us, when their actions satisfy our preferences.”
AI requires revisiting the social contract
The confrontation over AI ethics is clearly happening against a broader backdrop of confrontation over society’s priorities in many areas of the workplace, technology, culture and industrial practice.

“The digital realm is overtaking and redefining everything familiar even before we have had a chance to ponder and decide,” writes Shoshana Zuboff in The Age of Surveillance Capitalism.
Shoshana ZuboffThey are questions that have been raised numerous times in past with respect to machines and people. Shoshana Zuboff, author of books such as In the Age of the Smart Machine, and The Age of Surveillance Capitalism, has framed the primary ethical question as, “Can the digital future be our home?”
Some technologists have confronted practices that have nothing to do with AI but that fail to live up to what they deem just or fair.
Tim Bray, a distinguished engineer who helped build the Java programming language, last year quit Amazon after a five-year stint, protesting the company’s handling of activists among its labor rank and file. Bray, in an essay explaining his departure, argued that firing employees who complain is symptomatic of modern capitalism.
“And at the end of the day, the big problem isn’t the specifics of COVID-19 response,” wrote Bray. “It’s that Amazon treats the humans in the warehouses as fungible units of pick-and-pack potential. Only that’s not just Amazon, it’s how 21st-century capitalism is done.”
Bray’s reflections suggest AI ethics cannot be separated from a deep examination of societal ethics. All the scholarship on data sets and algorithms and bias and the rest points to the fact that the objective function of AI takes shape not on neutral ground but in a societal context.
Also: The minds that built AI and the writer who adored them
Reflecting on decades of scholarship by the entirely white male cohort of early AI researchers, Pamela McCorduck, a historian of AI, told ZDNet in 2019 that AI is already creating a new world with an incredibly narrow set of priorities.
“Someone said, I forgot who, the early 21st century created a whole new field that so perfectly reflects European medievalist society,” she said. “No women or people of color need apply.”
As a consequence, the ethical challenge brought about is going to demand a total re-examination of societies’ priorities, McCorduck argued.
“If I take the very long view, I think we are going to have to re-write the social contract to put more emphasis on the primacy of human beings and their interests.
“The last forty or more years, one’s worth has been described in terms of net worth, exactly how much money you have or assets,” a state of affairs that is “looking pretty awful,” she said.
“There are other ways of measuring human worth.”