
Natural Language Processing (NLP) has long played a significant role in the compliance processes for major banks around the world. By implementing the different NLP techniques into the production processes, compliance departments can maintain detailed checks and keep up with regulator demands.
Nearly every aspect of a bank’s back office — whether it’s within trade finance, credit, global market, retail, and more. All of these areas can benefit from document processing and the use of NLP techniques to get through the process more effectively.
Certain verification tasks fall beyond the realm of using traditional, rules-based NLP systems. This is where deep learning can help fill these gaps, providing smoother and more efficient compliance checks.
There are several challenges that make the rules-based system more complicated to use when undergoing check routines.
Variability is one of these challenges. For instance, compliance document screening consists of large numbers of different types of documents, such as ID, bill of lading, tax notice, invoice, and more. This requires practical management and control methods in order to maintain the variability.
Named-Entity recognition also presents issues. Named Entity Recognition is a method that extracts information to locate and classify entities such as people, places, and more. Entities can appear different under different circumstances, making it difficult to correctly distinguish. For example, Teheran street is located in Paris, however, Teheran is the capital of Iran.
Being able to differentiate every entity in a single document by looking at keywords is a lengthy task. The structure and format of the raw document can make it even more difficult; the number of pages, the data is presented in a table structure or the format is in a PDF.
Traditional NLP may not have the ability to catch synonyms or ambiguous entities, such as Orange which can be identified as a city, color, fruit, or more. Therefore, we need to take context into consideration to correctly identify and produce the right output.
Looking at the diagram below, there are various sentences. The machine learning model uses Named-Entity recognition (NER) to identify and classify segments of the sentence. As you can see there are 4 different categories that can be used to classify the entities. These are Locations (LOC), Miscellaneous (MISC), Organizations (ORG), and Persons (PER).
For example, if we take the first sentence “I heard that Paris Hilton stayed at the Hilton in Paris”. The Machine learning model would have some difficulty trying to distinguish the difference between ‘Hilton’ being classified as an Organisation and ‘Paris’ as a location, as it had learned that ‘Paris Hilton’ is a Person. Another difficulty for the model would be to distinguish is ‘Paris’ is considered a name or a city.
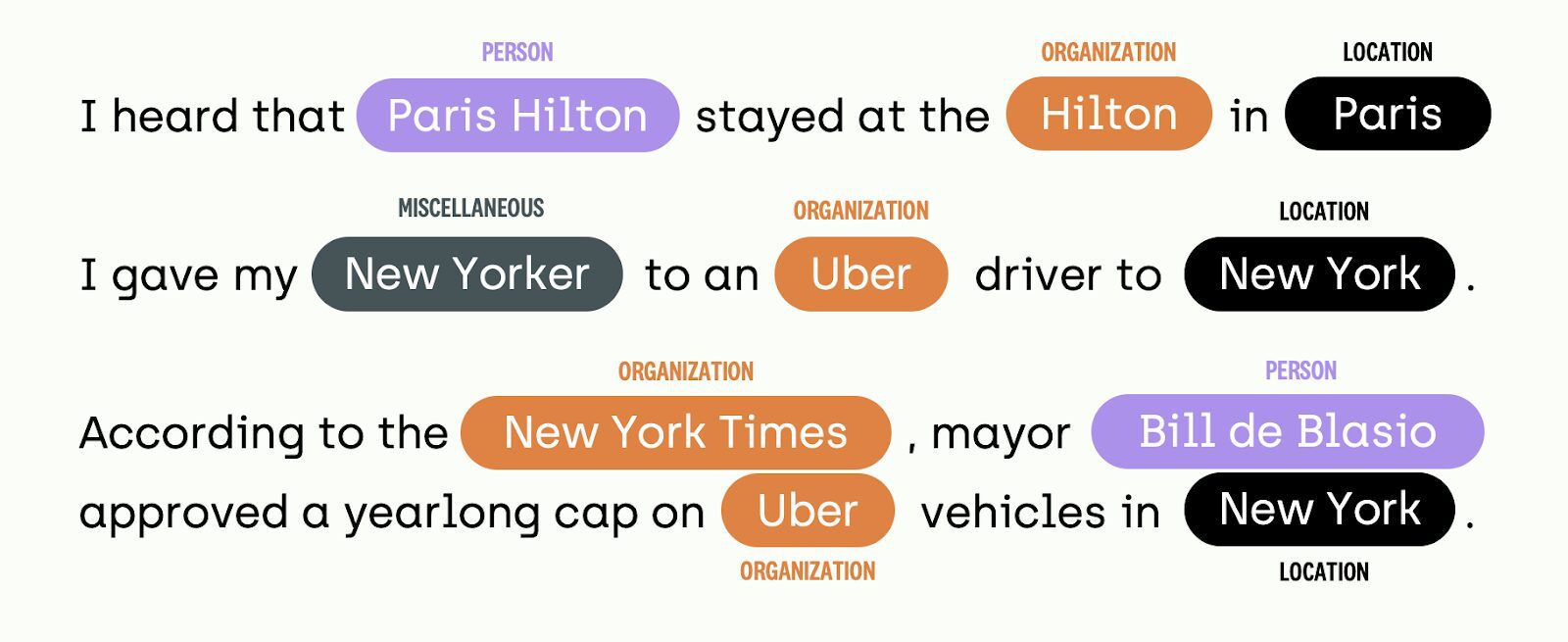
Based on the model’s knowledge base, it will have learned understanding of what entity is what through the training data. However, if the model has not learned these distinguishments in these entities, it would fail to produce the correct output. For example, if it had never classified ‘Paris’ as a Location before but has classified it as a Person, its past knowledge would tell it to classify it as a Person.
Therefore, training the model on various amounts of data and changing the training data will improve the overall performance of it producing the correct entity categories.
Another challenge when using traditional NLP document screening is increasing quality standards and changing regulations. A rule-based system has does not have the ability to define patterns, therefore trying to identify complex non-compliance patterns in textual documents is a big challenge for traditional NLP.

With the challenges faced by using manual or traditional NLP keyword-based screening, deep learning can solve the majority of these problems. Deep Learning is a subfield of machine learning, that imitates the way humans gain certain types of knowledge. Deep Learning techniques have become very popular due to their state-of-the-art accuracy, which has recently exceeded human-level performance.
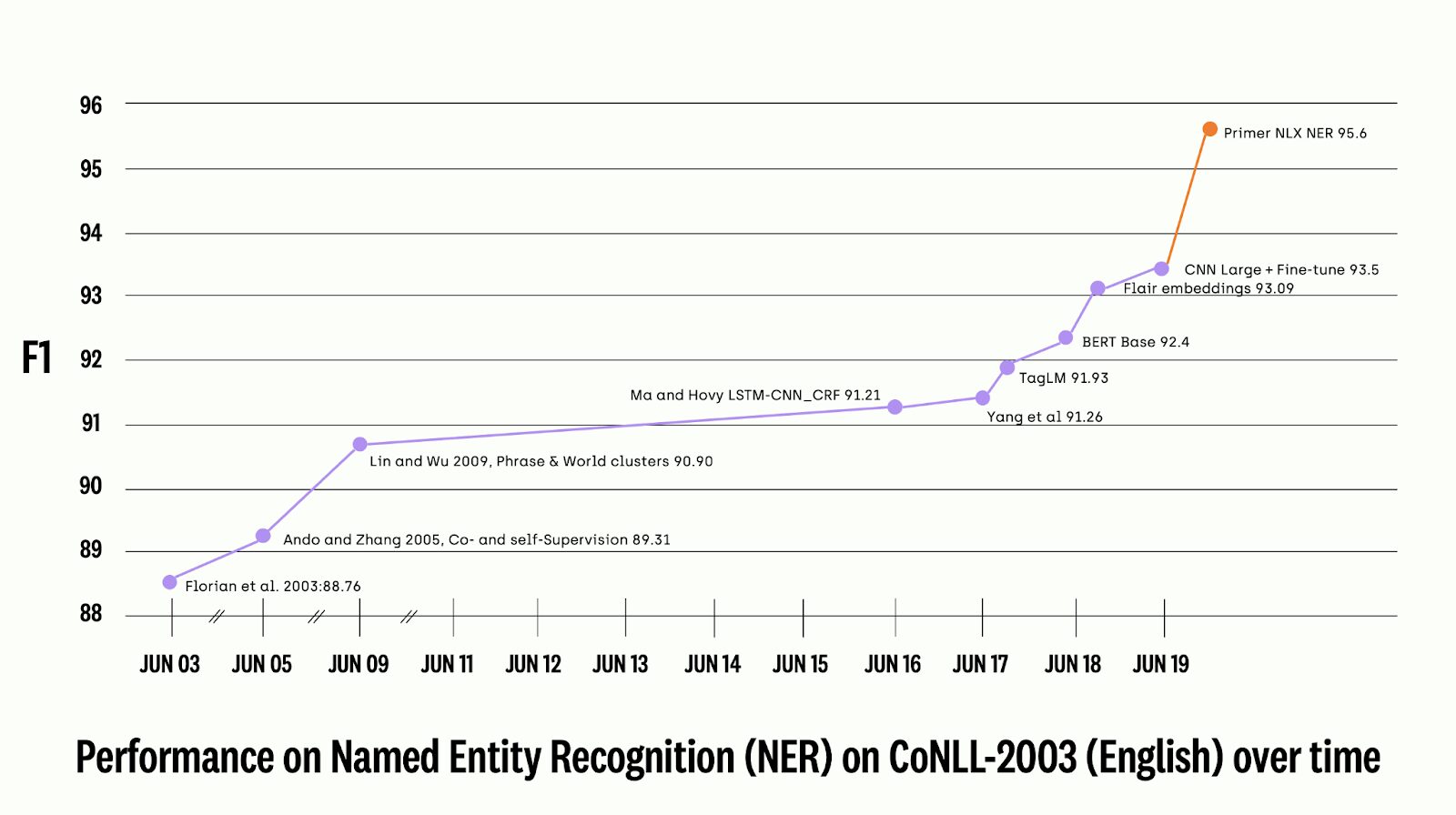
If you refer to the figure further down, it shows the performance of Named Entity Recognition on CoNLL from 2003 to 2020. The CoNLL 2003 NER task uses a model that inputs newswire text from the Reuters RCV1 that aims to identify four different entity types (PER, LOC, ORG, MISC).
The model is evaluated based on span-based F1 scores. Span-based QA is a task that consists of two texts, where one is called the context, and the other is called the question. The end goal is to extract the answer by using the question from the text, if it is available or not. The F1 score is determined by the following formula: F1= 2*precision*recall/(precision+recall). A low F1 score indicates both poor precision and poor recall.
The F1 scores since 2017 continuously increased starting at an F1 score of 91.26, to 93.5 in 2019 with CNN Large + fine-tune. The F1 score took a drastic growth in 2020 with the Primer NLX NER model achieving a 95.6% F1 accuracy score on CoNLL. This is a two-digit F1 score increase since the previously published CNN Large and Fine-Tune from Facebook AI Research. More importantly, the Primer NLX NER model is now on par with human-level performance.
Deep learning can reliably handle documents with high variability with the implementation of KYC (Know Your Customer), aswell as transaction monitoring and screening tasks.
It can also provide accurate analysis of complex data structures, mixed document types (e.g images and texts), and mixed models. It has the capabilities to adapt and learn documents, processes, and money-laundering/fraud scheme change.
Furthermore, another effective element of deep learning is that it allows end users to define entities upfront so that the software can easily recognise them.
Although deep learning software cannot replace traditional NLP, it still offers and works as a second line of defense. Deep Learning not only can identify, locate, and extract entities, it also have the ability to classify and categorize them.
Banks have a lot of data and documents which they have stored from past screenings. These can benefit deep learning models by using them as input data to train on. Over time, neural networks can be iteratively improved upon and adjusted to continuously improve the compliance analysis process.

Although there are many benefits to using deep learning and artificial intelligence (AI), they still come with their challenges. This includes scarcity of data, the complexity of integrating AI within existing infrastructure, and the inability to achieve lab results in the production phase.

There are various deep learning techniques you can use in order to solve problems in document analysis for compliance. However, an end-to-end platform simplifies the process and offers an efficient, easy method for continually improving your models for long-term success.
The end-to-end platform should offer a data-centric approach to AI, which involves feeding the model with clean, high-quality data (for example documents).
In order to do this, it must have:
- An ontology management and instructions that make it easy to efficiently define entities and categorise them accurately.
- A set of quality KPIs such as consensus and a review workflow to understand the overall ability of the ontology and the instructions and how to improve it over time.
- Smart tagging tools are important in achieving accurate labeling using human/machine collaboration.
- Digital interfaces allow cross-functional business/AI collaboration without the issue of data leakage, regardless of the location.
- Training tools in order to test, evaluate models, and to pre-label.
- An error analysis report such as Human/Model IOU that will have evaluated existing models.
Most businesses prefer to have full ownership of AI projects either by developing the project in-house or working with a vendor. My experience is that data-centric AI platforms offer a hybrid approach that combines:
- The first being the development and management of solutions in-house for IP and security reasons.
- The other being building their own AI NLP compliance checks systems regardless of the concern of shortages in the AI talent pool.
Edouard d’Archimbaud (@edarchimbaud) is a ML engineer, CTO and cofounder of Kili, a leading training data platform for enterprise AI. He is passionate about Data-centric AI, the new paradigm for successful AI.