
To examine the images, I used the read_coefficients function from torchjpeg. This function reads DCT coefficients directly from a JPEG file without decoding them, allowing me to examine low level details like chroma subsampling and quantization. This process revealed that one image in the training set is actually not a JPEG at all. It’s a PNG that someone renamed to have a .JPEG extension. In all it took around 4.5 hours to process the training set and around 10 minutes for the validation set. After processing I plotted the results. I’ve made all the data collection and plotting code available in this gist along with full size PDF plots.
Note that the Y axis on all charts uses a log scale.
Overall most of the images in ImageNet are compressed “lightly” and are quite small. The most common image size appears to be around 500 by 500 though there are some outlier sizes that are very large or oddly proportioned. For example, a 2592 by 3888 (very large) image, or a 500 by 33 image (oddly proportioned). This is important because most people resize images to 224 by 224 during preprocessing, and weird aspect ratios or much larger/smaller images will create artifacts from resampling.
The vast majority of the images are color images, are not chroma subsampled and were quantized at quality 96. This indicates very light compression which would not have a noticeable effect on the images. Of course there are exceptions here, such as 4:1:1 subsampling (which is VERY bad) and some quality < 10 images (also VERY bad). There also appears to be some disparity between the training and test sets for all of these parameters.
If you’re unfamiliar with any of the terms I used above, don’t worry I’ll be explaining everything as we dive into the results in detail.
Before we go any further: yes, “n02105855/n02105855_2933.JPEG” is actually a PNG that someone renamed to .JPEG. Here it is:
Opening it in a hex editor gives it away pretty clearly:
Not much else to say about it, except to note that it’s about an order of magnitude larger than the other images of comparable size.
Lets start simple, how many images are color and how many are grayscale.
Fairly straightforward, almost all the images are color. One thing to note about this though is that JPEG makes a distinction between a grayscale image stored with three color channels exactly the same and an actual grayscale image stored in one channel, what we’re counting here is the later: images which when loaded returned only one channel.
Next, let’s look at the image sizes, this section has some of the most interesting results. Image sizes are tricky to visualize, and plotting them graphically is very hard to interpret (I do have these graphs along with the plotting code in the gist), so instead I plotted the width and height on heatmaps. Because these are quite large, I cropped them to 1000×1000 for clarity (full size heatmaps are in the gist). Here’s the training set:
Each pixel in this map represents a size, for example the pixel at position (10, 70) shows the count of images that have a width of 10 and a height of 70. Brighter colors indicate more images.
We can see some interesting behavior. There’s a clear preference for width and height of 500, as well as some other intervals. and there are some interesting diagonal lines going from the top left to the bottom right of the map. Here’s the same image with some things labeled:
To make the interpretation of the diagonal lines easier, I overlayed a set of lines indicating aspect ratios 1:1 (red), 4:3 (green), and 3:2 (blue).
So we can see the lines correspond to these aspect ratios. 1:1 and 4:3 make sense, but 3:2 I only know of from 35mm film so frankly I’m sure how it ended up in here in such quantity.
Let’s briefly look at the same heatmap for the validation set:
Not only is it significantly more sparse (in fact almost all the images are in that 500 width or height area), but the aspect ratios are much more sensible. This is concerning because the size distribution in the validation set doesn’t reflect the training set.
Time for some pathological examples. Here’s an example of a small image from the training set, its size is only 20 by 17:
I have no idea what this is supposed to be, zooming doesn’t help, and I doubt your neural network could figure this out either.
Here’s one with a crazy aspect ratio, it’s 500 by 32:
I think it’s a ski? It’s sure to look weird after resizing to 224×224 with or without center cropping:
Next we can look at the chroma subsampling settings. I’ll first explain what chroma subsampling is, feel free to skip this section if you’re familiar, then I’ll go into the results.
What is chroma subsampling?
Human vision is less sensitive to small changes in color than it is to small changes in brightness. JPEG compression leverages this to save additional space by subsampling color information, in other words, it stores less color information than brightness information. The algorithm does this by converting the standard RGB image that it is given into the YCbCr color space. This color space separates the brightness or luma of a pixel from the color or chroma. The Y channel stores brightness, and is saved at full resolution. The Cb and Cr channels store color information (roughly blueness and redness respectively) and are often downsampled.
When we talk about how the downsampling is done, we use the following notation: “4:a:b”. This scheme refers to a 4 column, 2 row block of pixels. “a” indicates the number of color samples in the first row, and “b” indicates the number of these samples which change in the second row. So if we have 4:2:2 subsampling, we are saying that for every 4 luma samples, the first row only has 2 chroma samples, and both of them change in the second row. We interpret this as the chroma channels being half the width, but the same height as the luma channel.
The notation is strange at first but makes sense when you’re used to looking at it and I’ll fully explain the interpretation of the schemes when discussing results in the next section.
Results
Above you can see the chroma subsampling results. There are a couple of interesting things to note here, the first is that the vast majority of images are using “4:4:4” which means there is no subsampling. Around 10% use “4:2:0” meaning that the chroma channels are half the width and height. This is the most common setting in practice because it’s the default in many JPEG implementations, so if you’re deploying a system that’s going to work on real images, ImageNet might not be representative enough for you.
One thing that really stands out is the number of “4:1:1” images. This is a weird one (uncommon in practice), and it indicates that the chroma channels have only 1/4th the width of the luma channel (but the height is the same). This is going to incur a very large and noticeable degradation to the image. Also note that there are around an order of magnitude more of these in the validation set than there are in the training set, although they still make up a small fraction of the total images.
Here’s an example of a 4:1:1 image from the training set
Note how it looks terrible and the colors largely don’t make sense.
The setting that has the largest effect on the size and fidelity of a JPEG is its quality setting. This is actually non-standard but fairly common, anyone who has exported a JPEG file may be familiar with the slider that comes up asking for a quality from 0 to 100. Lower quality images look worse but are considerably smaller than high quality images. As in the last section I’ll first explain what this quality actually is, then we’ll look at the results.
What is JPEG Quality?
When a JPEG file is saved, it isn’t actually storing pixels, it’s storing coefficients of the Discrete Cosine Transform (DCT). The DCT is applied to the pixels to produce transform coefficients, these coefficients are then quantized by rounding them to save space. This rounding is the primary source of information loss in JPEG compression and is also responsible for the majority of its space saving. Essentially, the quality is used to control the amount of rounding, so high quality means less rounding resulting in a larger file. JPEG controls the rounding by computing a matrix from the quality factor which is used to element-wise divide the coefficients. Larger entries in this matrix means smaller coefficients after dividing and therefore more rounding. The rounding allows the coefficients to be represented as integers and creates runs of zeros and repeated elements (lower entropy representations).
Since quality is non-standard it is not stored in the JPEG file, and estimating quality is not always straightforward. I used the torchjpeg.quantization.ijg library to compute quantization matrices for every quality from 0 to 100 for each image until I found one that matched exactly the quantization matrix stored in the file. This is time consuming and it only works if the images were compressed using libjpeg, which luckily they all were.
Results
Above are the quality results. We can see a large spike at quality 96 indicating that the vast majority of images were compressed at this quality. 96 is very high, and wouldn’t noticeably effect the images. Interesting things to note here are the small proportion of very low quality (generally less than 10) images in the training set, these images would be almost completely destroyed by compression. Also note the sparsity of the validation set, where the training set covers a wide range of diverse qualities (albeit in small proportion), these are not generally represented in the validation set.
Here’s an example of a quality 3 image from the training set.
Note how it’s only somewhat recognizable and the colors are largely missing.
One thing that immediately stands out to me is that ImageNet seems to have been assembled from several very different sources, kind of like the Frankenstein’s monster of datasets. There was clearly a source that was assembled with great care for the compression settings, changing the defaults to quality 96 and 4:4:4 subsampling and using 500 by 500 images. Then there are some others which seem to lack that kind of intentional design but which are present in enough numbers that they appear to be related in someway. This may have been supplemented with single images from various sources which would explain some of the outliers. This can likely be corroborated by someone who knows the history of the dataset.
We can actually visualize this graphically. To do this, I stored the compression settings as 4D vectors (chroma subsampling type, width, height, quality) and projected them into 2D using UMAP [8]. I computed this on the training set and I used only 10% of the images with a width or height of 500 since those tend to dominate the signal otherwise. Here’s what that looks like, after I colored in some very clear clusters:
Examining these clusters gives us an idea of why they are grouped together. The orange cluster contains only size 500 by 375 images compressed at quality 96 and with 4:4:4 chroma subsampling. The green cluster contains 375 by 500 images (transposed of the orange cluster), with otherwise the same settings. The red cluster is again the same, but with 333 by 500 images.
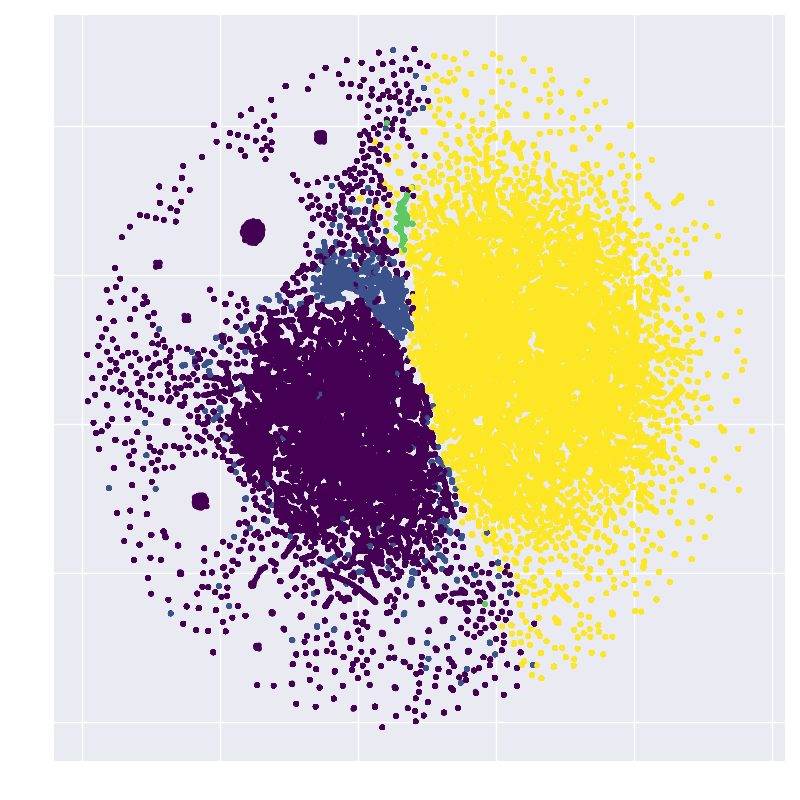
Next let’s color the points by chroma subsampling scheme
We get a nice, clear, separation on this one. Yellow points are 4:2:0 and purple points are 4:4:4, the rest are in between. A cluster of 4:2:2 (blue) shows up on the left hand side, looking back at the original plot above, this cluster sticks out a little more now that we’ve identified it.
Coloring the points by quality gives another interesting result
We can see lower qualities heavily represented on the lower right. This is the same region that 4:2:0 chroma subsampling was featured prominently.
If I had to guess based on these plots, I would say that the smaller clusters on the left hand side represent some initial sources of data. They have similar parameters, differ only in their dimensions, and are small in number. Around them on the left hand side are images which were gathered from other sources but with similar parameters. The right hand side represents a large departure in the method of data collection, with very different parameters represented. Take this with a grain of salt, because projection techniques like UMAP are not guaranteed to perfectly model the space, and this is just my speculation.