
Hear from CIOs, CTOs, and other C-level and senior execs on data and AI strategies at the Future of Work Summit this January 12, 2022. Learn more
Nvidia today detailed an AI system called GauGAN2, the successor to its GauGAN model, that lets users create lifelike landscape images that don’t exist. Combining techniques like segmentation mapping, inpainting, and text-to-image generation in a single tool, GauGAN2 is designed to create photorealistic art with a mix of words and drawings.
“Compared to state-of-the-art models specifically for text-to-image or segmentation map-to-image applications, the neural network behind GauGAN2 produces a greater variety and higher-quality of images,” Isha Salian, a member of Nvidia’s corporate communications team, wrote in a blog post. “Rather than needing to draw out every element of an imagined scene, users can enter a brief phrase to quickly generate the key features and theme of an image, such as a snow-capped mountain range. This starting point can then be customized with sketches to make a specific mountain taller or add a couple of trees in the foreground, or clouds in the sky.”
Generated images from text
GauGAN2, whose namesake is post-Impressionist painter Paul Gauguin, improves upon Nvidia’s GauGAN system from 2019, which was trained on more than a million public Flickr images. Like GauGAN, GauGAN2 has an understanding of the relationships among objects like snow, trees, water, flowers, bushes, hills, and mountains, such as the fact that the type of precipitation changes depending on the season.
GauGAN and GauGAN2 are a type of system known as a generative adversarial network (GAN), which consists of a generator and discriminator. The generator takes samples — e.g., images paired with text — and predicts which data (words) correspond to other data (elements of a landscape picture). The generator is trained by trying to fool the discriminator, which assesses whether the predictions seem realistic. While the GAN’s transitions are initially poor in quality, they improve with the feedback of the discriminator.
Unlike GauGAN, GauGAN2 — which was trained on 10 million images — can translate natural language descriptions into landscape images. Typing a phrase like “sunset at a beach” generates the scene, while adding adjectives like “sunset at a rocky beach” or swapping “sunset” to “afternoon” or “rainy day” instantly modifies the picture.
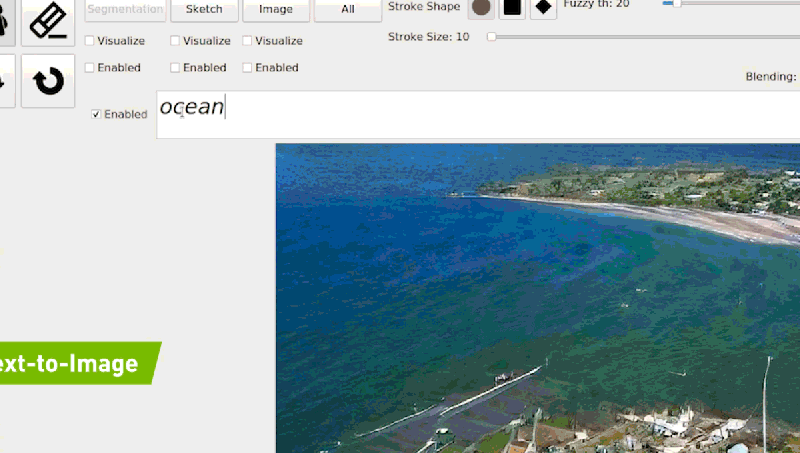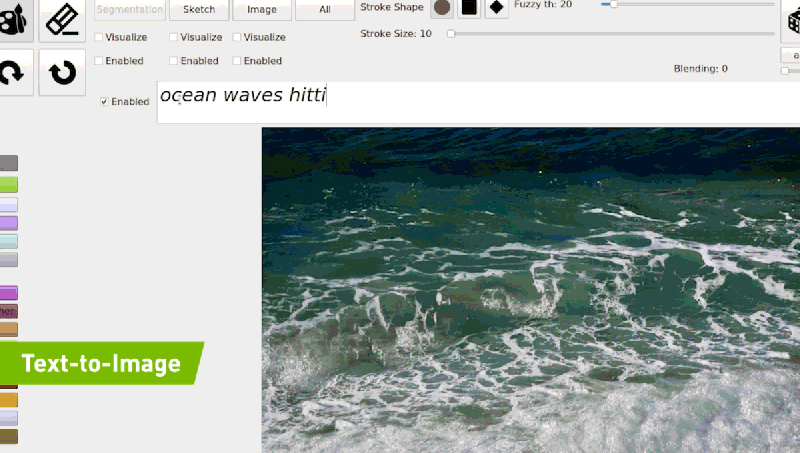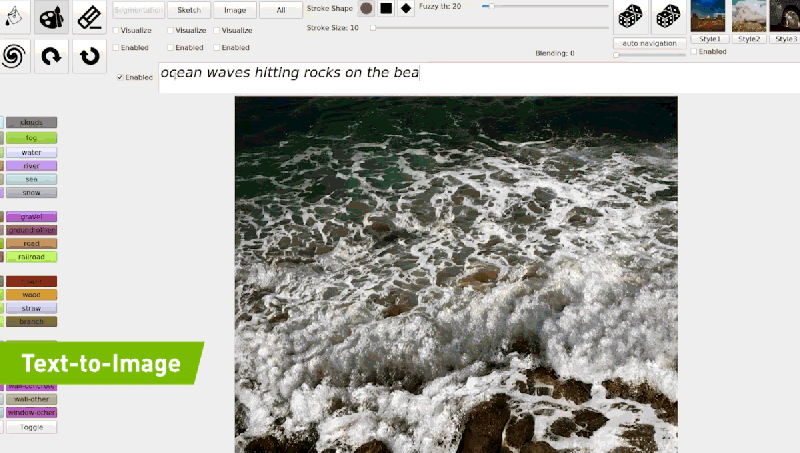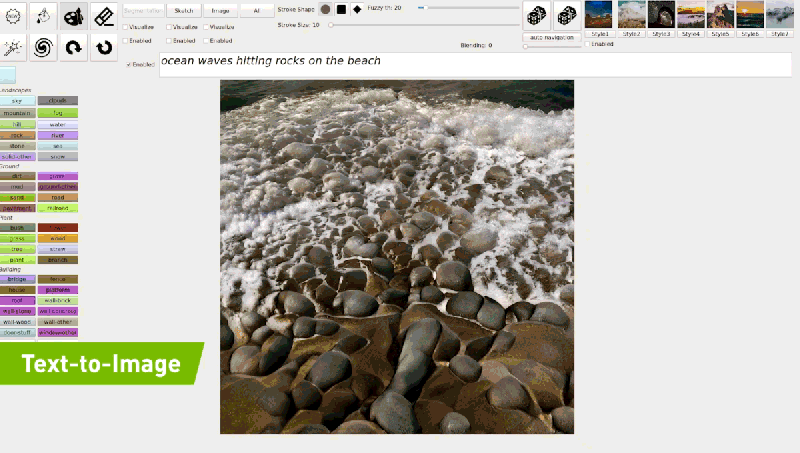
With GauGAN2, users can generate a segmentation map — a high-level outline that shows the location of objects in the scene. From there, they can switch to drawing, tweaking the scene with rough sketches using labels like “sky,” “tree,” “rock,” and “river” and allowing the tool’s paintbrush to incorporate the doodles into images.
AI-driven brainstorming
GauGAN2 isn’t unlike OpenAI’s DALL-E, which can similarly generate images to match a text prompt. Systems like GauGAN2 and DALL-E are essentially visual idea generators, with potential applications in film, software, video games, product, fashion, and interior design.
Nvidia claims that the first version of GauGAN has already been used to create concept art for films and video games. As with it, Nvidia plans to make the code for GauGAN2 available on GitHub alongside an interactive demo on Playground, the web hub for Nvidia’s AI and deep learning research.
One shortcoming of generative models like GauGAN2 is the potential for bias. In the case of DALL-E, OpenAI used a special model — CLIP — to improve image quality by surfacing the top samples among the hundreds per prompt generated by DALL-E. But a study found that CLIP misclassified photos of Black individuals at a higher rate and associated women with stereotypical occupations like “nanny” and “housekeeper.”

In its press materials, Nvidia declined to say how — or whether — it audited GauGAN2 for bias. “The model has over 100 million parameters and took under a month to train, with training images from a proprietary dataset of landscape images. This particular model is solely focused on landscapes, and we audited to ensure no people were in the training images … GauGAN2 is just a research demo,” an Nvidia spokesperson explained via email.
GauGAN is one of the newest reality-bending AI tools from Nvidia, creator of deepfake tech like StyleGAN, which can generate lifelike images of people who never existed. In September 2018, researchers at the company described in an academic paper a system that can craft synthetic scans of brain cancer. That same year, Nvidia detailed a generative model that’s capable of creating virtual environments using real-world videos.
GauGAN’s initial debut preceded GAN Paint Studio, a publicly available AI tool that lets users upload any photograph and edit the appearance of depicted buildings, flora, and fixtures. Elsewhere, generative machine learning models have been used to produce realistic videos by watching YouTube clips, creating images and storyboards from natural language captions, and animating and syncing facial movements with audio clips containing human speech.
VentureBeat
VentureBeat’s mission is to be a digital town square for technical decision-makers to gain knowledge about transformative technology and transact. Our site delivers essential information on data technologies and strategies to guide you as you lead your organizations. We invite you to become a member of our community, to access:
- up-to-date information on the subjects of interest to you
- our newsletters
- gated thought-leader content and discounted access to our prized events, such as Transform 2021: Learn More
- networking features, and more
You must be logged in to post a comment.